This year the Australian government is introducing a series of measures to restrict the availability of vapes, starting today.
The new reforms address loopholes in the current laws that allow easy access to highly addictive, flavoured, cheap, and harmful vaping products that are marketed to kids.
Vaping products will still be available through a prescription for anyone using them to quit smoking. But the Therapeutic Goods Administration will tightly regulate prescription-only vapes.
So what are the new regulations? And why are they needed?
Before the 2024 rule changes, vaping products imported and sold in Australia were required to be nicotine-free, unless accessed through a pharmacy with a prescription from a qualified health professional.
Individual users were also allowed to import nicotine-vapes from overseas through the Personal Importation Scheme, provided they had a valid prescription.
The vaping industry – including manufacturers, importers and retailers – exploited these loopholes and openly sold products containing nicotine to young people by falsely claiming the products were “nicotine-free”.
But the only way to tell the difference between a nicotine and nicotine-free vape is to test it in a lab – a time consuming and expensive endeavour, given the high volume of products imported.
So enforcing the nicotine/nicotine-free standards essentially proved near impossible against an industry determined to addict a new generation of users.
So what’s changing?
The new laws help tidy up the confusion and make the rules much clearer and easier to enforce.
They also address the ready access to vapes, which is the single biggest challenge to preventing young people from vaping.
The regulatory changes will be rolled out in three phases:
1. Importation ban
The first phase, being implemented from today, includes a ban on the importation of all disposable, single-use vapes. These are the products that are most popular with young people and come in a variety of flavours, including fruit, confectionery, cocktails and tobacco.
Single-use, disposable vapes cannot be refilled, but come in a wide range of sizes, from a few hundred of puffs, to upwards of 10,000 puffs.
Disposable vapes have flooded into Australia and fuelled the explosive rise in vape use among teens and young adults.
Disposable vapes come in a range of flavours that appeal to young people. E-Liquids UK/Unsplash
The importation of all other vapes, including refillable products, will be banned from March 1 2024, unless importers hold a licence and permit from the Office of Drug Control to lawfully import vapes. These legally imported vapes will only be sold in pharmacies to users with a prescription.
The Personal Importation Scheme allowance for vapes will also end on March 1 2024, meaning all vape users must access vaping products from a pharmacy in Australia.
This initial phase, while effectively stopping illegal vapes from coming in to Australia, doesn’t address the high volume of product that is already here. Retailers will be able to continue to sell their existing stock of “nicotine-free” vapes. But as we know, these products often do contain nicotine.
2. Domestic manufacture and sales ban
The next phase of reforms, expected to come into effect in late 2024, will eliminate the retail sale of all types of vaping products, regardless of their claimed nicotine content.
This second phase will include a ban on the manufacture, supply, advertising and commercial possession of vapes that fall outside of the prescription framework.
These changes will require amendments to the Therapeutic Goods Act 1989, and will likely be introduced in Autumn 2024 for federal Parliament’s consideration, but the exact date is yet to be set.
3. Prescription access
Vapes will only be available on prescription. Shutterstock
The prescription access to vapes for therapeutic purposes is also being changed to allow access to products that meet a quality standard.
From today, all medical and nurse practitioners will now be able to prescribe therapeutic vapes for quitting smoking or to manage nicotine dependence.
Further changes that strengthen the standards for therapeutic vapes are expected to be made by March 1 2024. For example, prescription vapes will have limits on the amount of nicotine, the types of flavours permitted, and be in standardised medical-style packaging.
What do the changes mean for vape users?
Vapes for therapeutic purposes will continue to be permitted in Australia and more medical professionals will be able to prescribe them. Prior to 2024, only select medical professionals could prescribe vapes (they had to register as an authorised prescriber). This is being widened to ensure the prescription model works as intended.
While vaping products will be available by prescription it’s important to know they remain unapproved medicines that have not been subjected to the same rigorous safety and effectiveness testing as other evidence-based quit smoking aids.
If you’re thinking of quitting smoking (or quitting vaping), get support by talking to your doctor, calling the Quitline (13 7848), or accessing help online.
Becky Freeman is an Expert Advisor to the Cancer Council Tobacco Issues Committee and a member of the Cancer Institute Vaping Communications Advisory Panel. These are unpaid roles. She has received relevant competitive grants that include a focus on e-cigarettes/vaping from the NHMRC, MRFF, NSW Health, the Ian Potter Foundation, VicHealth, and Healthway WA; relevant research contracts from the Cancer Institute NSW and the Cancer Council NSW; relevant personal/consulting fees from the World Health Organization, the Hong Kong Special Administrative Region Department of Health, BMJ Tobacco Control, the Heart Foundation NSW, the US FDA, the NHMRC e-cigarette working committee, NSW Health, and Cancer Council NSW; and relevant travel expenses from the Oceania Tobacco Control Conference and the Australia Public Health Association preventive health conference.
However, a boring indoor environment may not meet a cat’s need for mental stimulation. So how can we keep cats indoors in a way that will keep them safe and happy?
When considering animal welfare, the Five Domains Model is a good place to start. The five domains are:
nutrition – cats need the right type and amounts of food and water
physical environment, including temperature, flooring, noise, light
health – injury, disease, impairment
behavioural interactions with people and other animals, which includes the ability to exercise agency – choosing to engage, or not, in a particular activity at a given moment
mental state, including feelings such as hunger, pain, fear and comfort, which is an overall assessment of the animal’s subjective welfare state.
Keeping a cat indoors denies it the choice of being inside or outside. The sense of control an animal has over its life is an important aspect of its welfare, so how can we compensate for this loss of agency?
Several ways to help meet your cat’s needs are available at various price points. Most help meet the cat’s behavioural needs. Some also touch on other needs like environment or nutrition. All will contribute to your cat’s wellbeing.
If you’re feeling the pinch of the cost-of-living crisis, you can still provide your cat with plenty of enrichment for free, or at very low cost. There are multiple options.
Cat music has some scientific evidence behind it and is available on YouTube. This will help meet their environmental needs.
An example of the cat music available on YouTube.
Puzzle feeders, which you can buy or make yourself. Cats are predators, so they are biologically wired to work for their food. Puzzle feeders can be a good way to help meet this biological need.
These feeders don’t have to be expensive. One homemade example is an egg carton with the cat’s food inside and the lid closed, so the cat must find a way to open the carton to obtain the food.
Start with a simple puzzle, and gradually build to more complex puzzles. Only do puzzle feeding if your cat is a good eater and not underweight, though. This will help meet their nutritional and behavioural needs.
Clicker training uses a small noise-making device to indicate that the animal has performed a desired behaviour. While more commonly known for dogs, it can also be used in cats.
Cats can benefit from the interest and activities that clicker training can provide.
“Do as I do” training is another option. In this training style, the cat learns to mimic your behaviour, but in a species-appropriate way. For instance, if you stood on your tiptoes and raised your arms, your cat would stand on its hind legs and lift the front paws. This will be good for their behavioural needs.
New objects/scents will help meet their environmental needs. Cats enjoy novelty as long as there is also plenty of predictability in their environment. Regularly bringing new things or scents like catnip into your home may be interesting for your cat.
For more ideas about enriching your cat’s life indoors, check out this website.
Moderate outlay
If you’re tightening your belt but still have a little to invest in cat enrichment, there are lots of choices within the $10–$50 range to help meet the cat’s behavioural needs.
Harness walks (perhaps after some patient training) let your cat spend time outdoors in a safe way and get exercise.
Toys that move erratically are preferable to static toys. These can be toys that you move yourself such as a toy mouse that you move around on the floor. The movement may appeal to the cat’s predatory nature.
Puzzle feeders can be made very cheaply (see above), but you can buy one too. It can provide interesting variety for cats, especially after they’ve had some puzzle experience. Again, only do this with cats who are good eaters and are not underweight.
Remember, every cat is an individual. What works for some cats may not work for yours. Try preference testing – which require the cat to choose between different options or environments – to figure out your own cat’s favourite things.
Tiffani J. Howell does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Jenny Gordon, Honorary Professor, Centre for Social Research and Methods, Australian National University
Shutterstock
Australia has long thought of itself as the lucky country.
Whenever its economy has started to falter, a commodity boom has usually come along to restore prosperity… until in the 1980s, when the rest of the world failed to rescue us, and we embarked on a decade of reform.
I am afraid the world is going to fail to come to our rescue once again, and this time it’ll be harder to get a boost from reform because the easy reforms have already been done.
Here’s how I see our history from the earliest days of colonisation.
Exports kept making Australia rich
For most of those two or so centuries, we have been a commodity exporter, at first specialising in wool and wheat (mainly for the United Kingdom) and later specialising in minerals (initially for Japan).
We had to shift our focus quickly when the United Kingdom joined the European Economic Community in 1973.
Fortunately for us, Japan had surpassed the United Kingdom as our biggest customer the year before, in 1972, as our exports of minerals built steadily following the Australia-Japan Commerce Agreement signed in 1957.
Taiwan and South Korea later emulated Japan, buying our coal, iron ore and bauxite to modernise their cities as well as for manufacturing.
Demand for these commodities kept building until the late 1970s when it slowed as the East Asian economies matured.
Then came economic reform, and China
Demand stayed subdued throughout the 1980s and 1990s as Australia got on with economic reform, boosting the economy by letting in foreign banks, floating the dollar, cutting tariffs, removing cosy regulations and privatising enterprises in fields as diverse as airlines, airports, banking, telecommunications and energy.
By the early 2000s, China was a member of the World Trade Organisation and began demanding Australian iron ore and later coal and education, and the old pattern of commodity booms repeated itself, except this time bigger.
The usual pattern is growth in demand for Australian resources followed by a boom in foreign investment to develop those resources that pushes up the value of the dollar and boosts Australia’s buying power but makes its other exports less competitive.
When demand for resources falls, as is about to happen as China’s economy matures, Australians need to tighten their belts.
That’s unless Australia can find another big market or unleash another wave of economic reform.
China’s size makes the export boom we have just had hard to repeat. India has the population and an infrastructure deficit, but more of its own resources, and a more inward-focused growth strategy.
Indonesia has strong growth prospects, but faces challenges investing in infrastructure at scale in its densely populated chain of islands. And Australia faces competition from other commodity exporters. To keep prices high we need global demand to at least keep pace with potential supply.
Yet the International Monetary Fund is downgrading its global growth forecasts.
Geopolitical tensions, rising populism and protectionist sentiments, high debt levels and rising rates of natural disasters and climate-related disruptions are all downside risks for global growth, and, with this, the demand for commodities.
The one bright spot is the minerals needed for the energy transition, where demand exceeds forecast supply.
But Australia has many competitors in the supply of many of these minerals, and we failed to get a head start on the clean energy approaches to processing that would have given us an early advantage.
We’ll need reforms, but more subtle ones
So what are our options?
The reforms of the Hawke and Keating governments are still with us, but the declining role of government in the production of goods and services and a generally light-handed approach to regulation seems to have failed to prevent a decline in competition and, with it, a decline in economic dynamism.
While some of the government’s own actions might have dampened competition, it is entirely possible that the government’s withdrawal from all sorts of markets might be allowing those markets to become more concentrated.
It might even be that the government needs to change course again and reenter or better regulate some markets in order to force providers to lift their games.
While renationalisations are neither viable nor sensible, the energy transition and the projected growth of the care sector offer opportunities to reconsider the balance between the roles of government and the private sector.
The recently-announced Competition Review chaired by Kerry Schott is a step in the right direction.
The right solutions might be more subtle than those that worked in the 1980s. None of them should be off the table.
Jenny Gordon is an Honorary Professor at the Australian National University and a non-resident fellow at the Lowy Institute. She serves on the Asian Development Bank Institute Advisory Council.
There are few things more peaceful and relaxing than a night under the stars. Through the holidays, many people head away from the bright city lights to go camping. They revel in the dark skies, spangled with myriad stars.
As a child, I loved such trips, and they helped cement my passion for the night sky, and for all things space.
One of my great joys as an astronomer is sharing the night sky with people. There is something wondrous about helping people stare at the cosmos through a telescope, getting their first glimpses of the universe’s many wonders. But we can also share and enjoy the night sky just with our own eyes – pointing out the constellations and the planets, or discovering the joys of watching meteor showers.
It is easy to be bitten by the astronomy bug, and a common question I get asked is “how can I get more into stargazing?”. Here are ways to get started in this fascinating and timeless hobby that won’t break the bank.
Learning the night sky
A good place to start if you’re a budding astronomer is to learn your way around the night sky. When I was young, this involved getting hold of a planisphere (a star map, you can make your own here), or a good reference book.
Today, there are countless good apps to help you find your way around the night sky.
A great example of such an app is Stellarium – a planetarium program allowing you to view the night sky from the comfort of your room or to plan an evening’s observing ahead of schedule.
To memorise the night sky, you can try star hopping. Pick out a bright, famous, easy to find constellation, and use it as a guide to help you identify the constellations around it.
Learn one constellation per week, and within a year, you’ll be familiar with most of the constellations visible from your location.
Let’s use Orion as an example. The slider below shows images from Stellarium, with Orion riding high in the sky on a summer’s evening. I’ve added arrows to show how you can use Orion (shown in the centre of the map below) to hop around the summer sky.
To learn the constellations around Orion, your task is relatively straightforward. Head out on a clear, dark summer’s night, and find Orion high to the north. The three stars of Orion’s belt are a fantastic signpost to Orion’s neighbours.
If you follow the line of the belt upwards and to the right, you come to Sirius – the brightest star in the night sky, and the brightest star in Canis Major, the big hunting dog. Carry the line on and curve to the left as you go, and you’ll find Canopus, the second brightest star in the sky.
Now come back to Orion’s belt, and follow its line down and to the left. You’ll come to a V-shaped group of stars, including the bright red Aldebaran. This is the Hyades star cluster (with Aldebaran a foreground interloper), which makes up the head of Taurus, the bull.
Take the line further, and you come to the Pleiades – often known as the Seven Sisters – a beautiful star cluster easily visible to the naked eye.
Back to Orion again. This time, you’re going to draw a line from Rigel (the bright star at the top-left of Orion’s boxy body) through Betelgeuse (the bright red star at the lower-right of the box) and continue it towards the horizon. This takes you to Gemini – the twins.
Just by using Orion as the signpost, you can find your way to a good number of constellations (the cyan line points to Lepus, the hare; the white line to Canis Minor, the little hunting dog).
By star hopping, you’ll slowly but surely learn your way around the night sky until the constellations become familiar friends.
Looking at the sky with the naked eye is a wonderful thing, but it’s also great to zoom in and see more detail.
What if you don’t have access to binoculars or a telescope of your own? Thankfully, software like Stellarium can give you a fantastic virtual observing experience.
Imagine you want to see Saturn’s rings – a spectacular sight through even a small telescope. You can easily do this with Stellarium. Find Saturn by using the search bar and click on it to bring up the planet’s info.
Click on the cross-hair symbol to “lock on”, then zoom in. The further you zoom in, the more you’ll see. You can even run the clock forwards or backwards to see the planet’s moons move in their orbits, or the tilt of Saturn’s rings changing from our viewpoint over time.
A virtual observing session is as simple as that – just pan around the sky until you find something you want to see, and zoom in.
Example of using the clock feature in Stellarium to see the movement of Saturn’s moons. Stellarium
A hobby best shared
Now, a virtual observing session is great, but it pales compared to the real thing. I’d recommend using planetarium programs like Stellarium to figure out what you want to see, then heading out to look at it with your own eyes.
Astronomy is a wonderful hobby, and one that is best shared. Most towns and cities have their own astronomy clubs, and they’re usually more than happy to welcome guests who want to gaze at the night sky.
I joined my local astronomy society, the West Yorkshire Astronomical Society in the United Kingdom, when I was just eight years old. I owe them so much. The members were incredibly supportive of a young kid with so many questions, and I genuinely believe I would not be where I am today without their help. As a member, I saw firsthand just how fantastic the amateur astronomy community is.
The author Jonti Horner at age 16, showing then Astronomer Royal of the UK, Arnold Wolfendale (right), the WYAS 18-inch telescope, hand-made by members. Also seen is the society’s then president, Ken Willoughby. Alan Horner, author provided
At the society, we had weekly talks on astronomy, given by the club members and visiting astronomers from local universities. We also had regular night sky viewing nights, using the society’s very own telescope – a behemoth the members had built themselves.
People who are passionate about their hobby love nothing more than sharing it with others. The members of astronomical societies are fantastic guides to the night sky, and they often have incredible equipment they’re more than happy to share with you.
Both astronomy clubs and universities often offer public night sky viewing nights, which are the perfect opportunity to peer at the sky through a telescope, with an experienced guide on hand to find the most impressive sights to share.
So, if you want to learn more about the night sky, reach out to your local astronomy society – it could be the start of something very special.
If you want to find a local astronomy group, check out this list. If you’re a member of a group that isn’t listed, please reach out to get them to update the list using the ‘Contact Us’ link.
Jonti Horner does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Sadly, 2023 has been a violent one on the global stage. War broke out between Israel and Hamas in Gaza, leading to the deaths of thousands of Palestinians and hundreds of Israelis, including many children on both sides. And the bitter war between Russia and Ukraine continued with no end in sight.
As a result of the focus on these two conflicts, other countries have dropped off the radar for many people. Some of these nations have been dealing with simmering unrest, however, which could erupt in 2024 and seize the global spotlight.
So, where should we be watching in the coming year? Here are five places where I believe civil conflicts or unrest could worsen and potentially lead to violence.
Myanmar
Myanmar descended into chaos in 2021 when a military coup overthrew the democratically elected government led by Aung San Suu Kyi and sparked widespread civil protests that eventually morphed into an armed resistance.
The country, home to 135 ethnic groups, has rarely known peace. For years before the coup, there was a ongoing, low-grade civil conflict between the military and several minority ethnic groups who have long sought control over natural resources in their regions and independence from the state.
This exploded after the coup as ethnic militia groups joined forces with pro-democracy fighters from the Bamar majority protesting the junta.
Their resistance escalated in late 2023 with a coordinated northern offensive dealing the military its most significant losses in many years.
Insurgents won control of towns and villages on the northeastern border with China, including control over key trade routes. This led to renewed fighting in western Rakhine state, as well as in other areas.
The tenacity of the resistance of these minority groups, paired with the refusal of the military to compromise, suggests the country’s civil war may worsen considerably in 2024 and regain international attention.
Mali
In Mali, a nation in the turbulent Sahel region of Africa, tensions escalated throughout 2023 and now threaten to erupt into full-scale civil war.
Mali has long battled insurgent activity. In 2012, Mali’s government fell in a coup and Tuareg rebels, backed by Islamist militants, seized power in the north.
A United Nations peacekeeping mission was established in 2013 to bring stability to Mali. Then, in 2015, key rebel groups signed a peace agreement with the Mali government.
After two more coups in 2020 and 2021, military officers consolidated their power and said they would restore the state’s full territorial control over all of Mali. The regime insisted the UN peacekeeping mission withdraw from the country, which it did in June 2023. Subsequently, violence broke out between the military and rebel forces over future use of the UN bases.
In November, the military, reportedly backed by Russia’s Wagner Group, took control of the strategic northern town of Kidal which had been held by Tuareg forces since 2012. This undermines the fragile peace that has held since 2015.
It is unlikely the military will regain complete control over all rebel-held areas in the north. At the same time, insurgents are emboldened. With the 2015 peace agreement now all but dead, we can expect increased volatility in 2024.
Lebanon
In 2019, widespread civil protest broke out in Lebanon against leaders who were perceived not to be addressing the day-to-day needs of the population.
The International Monetary Fund criticised Lebanon in September for a lack of economic reform. The Lebanese government has also failed to reach agreement on appointing a president, a post that has been vacant for more than a year.
This risks undermining the fragile power-sharing arrangement in Lebanon in which the key political posts of prime minister, speaker and president are allocated to a Sunni-Muslim, Shia-Muslim and Christian Maronite, respectively.
Most recently, the war between Israel and Hamas has threatened to spill over to Lebanon, home to the Hezbollah militant group, which claims to have an army of 100,000 fighters. Importantly, this jeopardises tourism as a key hope for Lebanon’s economic recovery.
These factors may precipitate a more serious economic and political collapse in 2024.
Pakistan
Since Pakistan’s independence in 1947, the military has played an interventionist role in politics. Though Pakistani leaders are popularly elected, military officials have at times removed them from power.
In 2022, Pakistani Prime Minister Imran Khan fell out of favour with Pakistan’s militant leaders. He was subsequently ousted from power in a parliament vote and later arrested on charges that his supporters claim are politically motivated.
Violent demonstrations broke out nationwide after his arrest – a display of anger against the military that was once unthinkable.
Pakistan also faces spillover from instability in neighbouring Afghanistan and increased terror attacks. These security challenges have been compounded by a struggling economy and ongoing costs from the devastating 2022 floods.
Pakistan is expected to hold parliamentary elections in February 2024, after which the current military caretaker government is expected to transfer power back to civilian rule. Many are watching the military closely. If this transfer of power does not take place, or there are delays, civil unrest may result.
Sri Lanka faced a debilitating economic crisis in 2022 that led to critical fuel, food and medical shortages. Civil protests caused then-President Gotabaya Rajapaksa to flee the country. He was quickly replaced by current President Ranil Wickremesingh.
Stability returned in 2023 as Sri Lanka began implementing economic reforms as part of a bailout agreement with the International Monetary Fund. However, widespread dissatisfaction with political elites and the underlying drivers of the country’s economic hardship have not been addressed.
Elections are also due in Sri Lanka by late 2024. While Wickremesingh, the incumbent, is likely to run for a second term, he has low trust with the public. He is viewed as too close to corrupt political elites.
This dissatisfaction could lead to renewed protests – particularly if the economy stumbles again – in a repeat of the situation that led to Rajapaksa’s ousting in 2022.
Jessica Genauer does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Emma Beckett, Senior Lecturer (Food Science and Human Nutrition), School of Environmental and Life Sciences, University of Newcastle
It’s an unfortunate quirk of evolution that vegetables are so good for us but they aren’t all immediately tasty to all of us. We have evolved to enjoy the sweet or umami (savoury) taste of higher energy foods, because starvation is a more immediate risk than long-term health.
Vegetables aren’t particularly high energy but they are jam-packed with dietary fibre, vitamins and minerals, and health-promoting compounds called bioactives.
Those bioactives are part of the reason vegetables taste bitter. Plant bioactives, also called phytonutrients, are made by plants to protect themselves against environmental stress and predators. The very things that make plant foods bitter, are the things that make them good for us.
Unfortunately, bitter taste evolved to protect us from poisons, and possibly from over-eating one single plant food. So in a way, plant foods can taste like poison.
For some of us vegetables are very bitter. Shutterstock
For some of us, this bitter sensing is particularly acute, and for others it isn’t so bad. This is partly due to our genes. Humans have at least 25 different receptors that detect bitterness, and we each have our own genetic combinations. So some people really, really taste some bitter compounds while others can barely detect them.
This means we don’t all have the same starting point when it comes to interacting with salads and veggies. So be patient with yourself. But the steps toward learning to like salads and veggies are the same regardless of your starting point.
We can train our tastes because our genes and our receptors aren’t the end of the story. Repeat exposures to bitter foods can help us adapt over time. Repeat exposures help our brain learn that bitter vegetables aren’t posions.
And as we change what we eat, the enzymes and other proteins in our saliva change too. This changes how different compounds in food are broken down and detected by our taste buds. How exactly this works isn’t clear, but it’s similar to other behavioural cognitive training.
The good news is we can use lots of great strategies to mask the bitterness of vegetables, and this positively reinforces our taste training.
Salt and fat can reduce the perception of bitterness, so adding seasoning and dressing can help make salads taste better instantly. You are probably thinking, “but don’t we need to reduce our salt and fat intake?” – yes, but you will get more nutritional bang-for-buck by reducing those in discretionary foods like cakes, biscuits, chips and desserts, not by trying to avoid them with your vegetables.
Adding heat with chillies or pepper can also help by acting as a decoy to the bitterness. Adding fruits to salads adds sweetness and juiciness, this can help improve the overall flavour and texture balance, increasing enjoyment.
Pairing foods you are learning to like with foods you already like can also help.
The options for salads are almost endless, if you don’t like the standard garden salad you were raised on, that’s OK, keep experimenting.
Experimenting with texture (for example chopping vegetables smaller or chunkier) can also help in finding your salad loves.
Challenging your biases can also help the salad situation. A phenomenon called the “unhealthy-tasty intuition” makes us assume tasty foods aren’t good for us, and that healthy foods will taste bad. Shaking that assumption off can help you enjoy your vegetables more.
When researchers labelled vegetables with taste-focused labels, priming subjects for an enjoyable taste, they were more likely to enjoy them compared to when they were told how healthy they were.
The bottom line
Vegetables are good for us, but we need to be patient and kind with ourselves when we start trying to eat more.
Try working with biology and brain, and not against them.
And hold back from judging yourself or other people if they don’t like the salads you do. We are all on a different point of our taste-training journey.
Emma Beckett has received funding for research or consulting from Mars Foods, Nutrition Research Australia, NHMRC, ARC, AMP Foundation, Kellogg, and the University of Newcastle. She also works for FOODiQ Global. She is a member of committees/working groups related to nutrition or the Australian Academy of Science, the National Health and Medical Research Council and the Nutrition Society of Australia.
Source: The Conversation (Au and NZ) – By Chris McMillan, Professional Teaching Fellow in Sociology, University of Auckland, Waipapa Taumata Rau
The recently concluded men’s Cricket World Cup in India reached record audiences. But there was one thing the organisers did not want those viewers to see (other than India’s defeat by Australia in the final): cricket’s own climate crisis.
Along with battling heat and humidity, players were forced to contend with unhealthy air created by pollutants from vehicles, factories and construction, and aggravated by increased temperatures in 20 of the 47 matches.
The United Nations describes the threat more forcefully. Secretary-General António Guterres has warned the world is on a “catastrophic path” to a “hellish future”. It is a future that threatens the very viability of cricket.
Cricket and the climate Crisis
As an outdoor summer game in which the natural environment plays a unique role, cricket is perhaps the pitch sport most at risk from a changing climate.
Increased temperatures and heat waves threaten the safety of players and spectators, as well as the preparation and maintenance of playing surfaces.
Equally, cricket is vulnerable to higher risks of drought and flooding. Air pollution, especially in the Indian subcontinent, continues to cloud the game.
The threat is compounded by the precarious regions in which cricket is played. Bangladesh and Pakistan – where New Zealand’s Black Caps played their past two overseas Test series – are ranked seventh and eighth respectively for vulnerability on the Climate Risk Index.
At the same time, cricket is not merely a potential victim of the climate crisis, it is a contributor to it.
While it lags behind other sports in calculating its environmental impact, cricket is a resource-heavy game. Preparation of a cricket field requires around 60,000 litres of water a day. An expanding international touring schedule means regular long-haul flights.
One of the few existing studies estimated an Indian Premier League match produced about 10,000 tonnes of carbon dioxide. Overall, cricket’s carbon footprint is substantial.
For a game facing a potential existential crisis, cricket’s sustainability efforts have been slow by comparison with other sports.
In line with the Paris Agreement, the International Olympic Committee has committed to a 50% reduction in direct and indirect carbon emissions by 2030, and promised the 2032 Brisbane Olympics will be “climate positive”.
Both FIFA and World Rugby have sustainability plans, as do Formula One and most American sports leagues, including the NBA. Sail GP even has an “Impact League” that measures environmental mitigation efforts.
While some scepticism might be warranted – FIFA held a World Cup in oil-rich Qatar, and the 2030 men’s tournament will be held across two continents – at least the intent is clear.
By contrast, the International Cricket Council has not published a sustainability strategy. Of its full members, only the England and Wales Cricket Board has such a plan.
Of the more than 200 sporting organisations to sign up to the UN’s Sports for Climate Action Framework – which requires participants to halve emissions by 2030 and reach net zero by 2040 – only six are cricketing entities, and most are in England.
Inaction in New Zealand
New Zealand Cricket (NZC) is as silent on climate as many of its global counterparts. Environmental sustainability does not appear in NZC strategy documents.
At the same time, its 2022-23 annual report laments that less than half of all scheduled recreational fixtures could be played in some areas due to rain and flooding. It also notes the “cyclones, floods and related civil emergencies” that caused these cancellations were “well beyond its control”.
New Zealand’s 2023-24 cricket season could be the hottest yet. Following the devastating floods in Auckland in early 2023, a drought is possible this summer. Heat waves are becoming more persistent and more dangerous.
Cricket is not made for such extremes. At a time when game is struggling to attract participants, climate change is making it harder for recreational cricketers to play.
We think ahead and pay it forward. It’s about doing the right things for the best reasons. Leading the way, and following our own path. We never give up, give in, or say die.
It may be time to apply those admirable sentiments to its response to the climate crisis. The first step would be to sign up to the UN Sport for Climate Action Framework – and get some sustainability runs on the board.
Chris McMillan does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Penny van Oosterzee, Adjunct Associate Professor James Cook University and University Fellow Charles Darwin University, James Cook University
Shutterstock
First Nations people please be advised this article speaks of racially discriminating moments in history, including the distress and death of First Nations people.
On October 9 1873, George Augustus Frederick Dalrymple reclined in a boat on the glorious North Johnstone River in the coastal Wet Tropics. Dalrymple was in raptures. A riot of palms, bananas, ferns and lilies descended to the waters edge, and large-leafed taro grew in strips along the riverbank over tens of hectares. He came across a large village with rows of neatly made bark and palm leaf huts. Dappled paths led to managed patches of open forest, groves of fruit trees, bananas and yams. Nearby, a small fleet of moored catamarans sat bobbing.
In the colonial literature, there are many such descriptions of beautiful and bountiful pre-European tropical landscapes. It was clear that people had helped create such a rich paradise through their land management
By 1886, many rainforest people of tropical north Queensland had been “dispersed” – killed – and swathes of this biodiversity hotspot began being cleared for sugarcane.
First Nations groups such as Australia’s rainforest people had skilfully managed entire ecosystems over the long term, in what has been termed “ecology on steroids”. These future-making methods protected landscapes from climate change and buffered them against extinction.
Australia’s First Nations did this through the cold and dryness of the last ice age, and as the seas rose through the droughts and floods of the El Niño Southern Oscillation climate cycle.
As we face an uncertain climate future, it’s valuable to look at how people weathered such change.
Decoupling landscape from climate change
When people first came to Australia, the Wet Tropics were not wet. The Pleistocene climate was cool and windy, with mega monsoons and long periods of diabolical drought. If you had looked east from what is now Cairns, you would have seen not oceans and coral atolls, but plains and valleys filled with grasslands and forest. The sea lay tens of kilometres off the continental shelf.
The oldest record of human occupation in Australia is found in the Top End. Here, in a magnificent cave system in Arnhem Land, people prepared a meal of native fruits and processed pandanus using an adaptable toolkit. This meal took place 65,000 years ago, when savannah stretched all the way to the island of New Guinea.
When the sea levels were lower, people could walk from Australia to Papua New Guinea. Girraween lagoon is marked on the map. Michael Bird/Damien O’Grady, CC BY-ND
Over thousands of years, Australia’s people developed a vibrant cosmology. For First Nations people Country was sentient. The land was not a mindless resource but part of your family – and came with family obligations. Everyone, whether you were human, an animal, a plant, a river, fire, the sky or wind, was closely watched. People were embedded within ecosystems.
Recently scientists sampled the deep mud of Girraween lagoon in the Top End searching for pollen and charcoal that would provide a window into this deep time.
The deep mud of Girraween lagoon near Darwin is a window into the past. Michael Bird/Damien O’Grady, CC BY-ND
Some 13,000 years ago, the landscape was parched. But as the northern hemisphere ice sheets melted, the seas rose and the monsoons began to return. By the mid-Holocene, between 9,000 and 4,000 years ago, the monsoons were arriving regularly. The lagoon filled up, nestled in a landscape of moisture-loving shrubs and brushed by relatively cool fires.
But then, the climate lurched to one of the long periods of horrendous drought instigated by an El Nino weather system.
Curiously, destructive fires did not follow. The deep mud core showed fire became less, not more, intense, as the forest shaded out the volatile grasses that cause intense fires in savanna. Even as drought increased, the Top End landscape filled with layers of diverse herbs and shrubs, with a variety of trees and groves of monsoon forest closer to the lagoon.
This patterning was likely the handiwork of people taming fire and putting it to work. Through patch burning, they created a rich landscape of diverse habitat that sustained people and created niches for a wide range of species.
Today, a quarter of Australia’s fire-prone savannahs, mostly managed by First Nations peoples, are returning to patchy fire regimes. These reduce the big wildfires associated with European pastoralism and reduce emissions.
Perhaps few places encapsulate the harshness of Australia’s environment more than the Great Sandy Desert. From before the last ice age, the ancestors of today’s Martu people would have witnessed great floods rushing down the Sturt Creek into an extensive lake system, Paruku (Lake Gregory). These lakes were ten times larger than today’s system, ringed by dunes covered in scrubby vegetation and flammable spinifex.
In the 1960s, the Martu were forced to leave to make way for nuclear missile tests. Without cultural burning, it took mere years for fuel to build up and large wildfires to incinerate the landscape.
You can see the change clearly. Satellite images and aerial photograhy showed the size of the average fire went from 64 hectares under Martu management to over 50,000 ha by the 1980s.
Mosaic burning reduces fire intensity and promotes fresh growth. Stefani Crabtree, CC BY-ND
In turn, this drove dramatic shifts to the food web. Over the two decades of Martu absence, ten species of small mammal became locally extinct, including the rufous hare-wallaby, burrowing bettong, bilby, mulgara and brushtail possum. What’s more, 14 mammals, three birds and two reptiles became threatened. Cats, foxes, camels and buffel grass became widespread.
In the 1980s, the Martu were able to return. Back on Country, they worked with scientists to reconstruct pre-1960s food webs from their memories, recalling not only species hunted, but rich detail of the behaviour, interactions and life histories.
This return to First Nations management is long overdue, as human-made climate change intensifies. We will need to relearn these ancient techniques of managing country on a broader scale to cope with the changes to come.
Penny van Oosterzee is a Director of Biome5 Pty Ltd which was a linkage partner in an ARC research project on cost-effective restoration for carbon and biodiversity based on her property Thiaki. Penny has recently published a book, Cloud Land, with Allen & Unwin based on the Thiaki restoration project. The book focuses on Australia’s Wet Tropics Rainforest and Rainforest peoples.
Barry Hunter is a Djabugay man and chair of Terrain NRM, a natural resources management group.
Imagine the dentist has just said you urgently need a A$2,000 dental crown. A week later, a pipe in your bathroom bursts, causing $8,000 worth of damage. Suddenly, you’ve been hit with a $10,000 financial shock.
As the cost-of-living crisis plunges more households into financial uncertainty and at least one-third of Australians struggle to make ends meet, it’s more important than ever to ask yourself: how financially resilient am I?
Being financially resilient means you aren’t left financially devastated when an expensive emergency creeps up on you. Here are five key signs of financial resilience.
1. You have a plan for what you’d do if you suddenly lost your salary
Financial resilience means having a plan to fall back on during tough times. This extends to how you’d make money if you lost your job.
In practice, that means things like making sure your skills and contacts are kept up to date so you can more easily find a new job. You might also consider whether a “side hustle” job such as tutoring could work for you in the short term, and how you’d put that plan into practice if needed. Perhaps you have a spare room in your home you could rent out for a period of time if you lost your salary.
Those examples won’t work for everyone, of course, but it’s still worth asking yourself the question: what would I do if I lost my salary tomorrow?
It’s good to think about how you’d handle a difficult financial situation – well before disaster strikes. Shutterstock
2. You have enough liquid assets to meet an unexpected financial expense
Liquid assets means money that can be accessed quickly and easily to overcome an unplanned financial expense. Savings are a good example. They provide a buffer so you can cope in the short term if a financial shock strikes. The federal government’s Moneysmart website suggests you aim to have enough in your emergency savings fund to cover three months of expenses.
Having an offset account as part of a mortgage is another option that provides a buffer. Putting money in an offset account helps you save while reducing the amount of interest on a home loan. You can still access the money in an offset account at any time.
3. You have bought the right financial products, such as insurance
Financial products, such as insurance, hedge against potential losses.
Personal insurance is important because it provides income in the event of death, illness or injury. Examples include:
life insurance (which pays out to your beneficiaries, such as your partner or children, when you die)
total and permanent disability insurance (which means you may get some money if you acquire a disability that prevents you from working)
income protection (which provides you with an income if you can no longer work)
trauma cover (which covers a life-changing illness or injury, such as cancer or a stroke).
Check if your superannuation has any of these insurances included in it. Research has found that many Australians are underinsured.
4. You can still pay your debts when times are tough
Being able to borrow money can help when you’re in a tight spot. But knowing where to borrow from, how much to borrow and how to manage debt repayments is crucial.
Financially resilient people use debt responsibly. That means:
not using debt for frivolous expenses like after-work drinks
staying away from private money lenders
being cautious about buy-now-pay-later services
watching out for debts with high interest rates, such as payday loans and credit card debt
maintaining debt repayments consistently.
If you’re having debt problems, talk to your lender about renegotiating your repayment arrangements, or contact the National Debt Helpline on 1800 007 007.
Credit card debt can come with high interest rates. Shutterstock
5. You are financially literate
Being financially literate means you can assess the benefits and risks of using savings or taking out debt to meet an unplanned financial need.
As I have written before on The Conversation, key signs of financial literacy include tracking your cashflow, building a budget, as well as understanding what debts you have and which to pay first.
It also means storing your money across different places (such as superannuation, savings accounts, property and the share market) and understanding how financial assets like cash, shares and bonds work.
Being aware of your financial strengths and weaknesses, and having financial goals is also important.
Nobody is born knowing how to make sound financial decisions; it’s a skill that must be learned.
It’s good to think about the resources you would draw upon to help get yourself out of a difficult financial situation – well before disaster strikes.
Bomikazi Zeka does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
I thought convincing my husband of the merits of my returning to study just as he had retired would be a very tricky sell. So his enthusiasm for the idea caught me by surprise.
He helpfully suggested several interesting topics: sea turtles, dugongs and coral reefs. If it involved a boat in a warm climate, he was behind me 100%.
But if you are going to dedicate three and a half years to studying a single topic, it really needs to excite you, and my interest in gut bacteria and health won out. Much to my hubby’s dismay, I chose to immerse myself in the subject of marsupial poo – and in retaliation he started calling me Dr Poo.
Fortunately, I am not alone in my faecal fetish. As any wildlife carer can tell you, monitoring what comes out of an animal is a vital part of keeping an eye on its health.
So when I set out to find volunteers to collect poo from wild and captive marsupials – specifically eastern grey kangaroos, swamp wallabies, red-necked wallabies, bare-nosed wombats, and ringtail and brushtail possums – over an area from Queensland to Tasmania, it was mainly wildlife carers who answered the call.
The Marsupial Microbiome Poop Troop
I enlisted a core group of around 20 people who, every season, dutifully went out in all weathers, armed with their forceps and zip-lock bags, to select fresh pellets from their in-care residents or wild animals that passed through. Then they filled in the paperwork, carefully labelled the bags and stored them in freezers until they could be posted in special temperature-controlled packaging to the university for genetic analysis.
We did this to establish a baseline of what the normal wild gut microbiome looks like in different animals in different areas at different times of the year. This lets us recognise if there is an imbalance in captive animals that can be addressed and prevented by changing diet or introducing supplements.
A collection of precious kangaroo poo. Diane Lane
To aid my communication with these wonderful volunteers, I started a Facebook group page which became known as the Marsupial Microbiome Poop Troop. And it has some colourful members.
There is Kate, who obtains the freshest wombat poo by stalking wild wombats in her local reserve until they produce the goods. Don’t try this at home. Kate has serious wombat-whisperer skills.
There’s Darryl, who was devastated when the roof blew off his house in a storm and he was without power for two weeks. Not for his wrecked house or loss of possessions, but because his collection of possum poo thawed and he had to throw it away and start again.
Julie wins the prize for most prolific collector. Her poo parcels are the largest by far, and cover quite a few species. The supervisor of the university’s stores, who receives the poo parcels, is not always a fan of Julie’s efforts. He must have highly attuned olfactory senses as he routinely sends me emails announcing the arrival of more “animal excrement” or “malodorous packages” for immediate collection.
Saving orphaned joeys
While it all sounds like fun and games, the research we do with the collected poo has serious potential to save many marsupial lives. We have a particular focus on young orphaned joeys.
Whether their mothers were hit by cars, attacked by dogs, or died of other causes, the joeys arrive at wildlife shelters stressed, often injured, and generally cold and hungry. Because marsupials are born so undeveloped – and normally spend a long time in their mother’s pouch – they require an extended period in care when orphaned.
The gut microbiome of these “pinky” joeys is equivalent in development to that of premature human babies. It is still being established at this crucial time, via the mother’s milk, environmental conditions in the pouch, cleaning and grooming.
The sudden loss of parental care, coupled with the stress of being in captivity and a complete change of diet, can do a great deal of harm to the gut microbiota. This can leave the joey open to infections, diarrhoea and dehydration, which can be fatal.
If it were possible to fix this imbalance, the success rate of rearing orphaned marsupials would rise. Their improved general health should mean greater numbers of animals successfully reintroduced to the wild.
While the animals involved in this study are considered “common”, the same principles may be applied to endangered species held in captive breeding programmes once it has been shown to work on the more prolific species.
Without the help of the Poop Troop volunteers, it would have been impossible to sample so widely and consistently. The remaining poo will be kept frozen and made available to future researchers, so these wonderful people have, through their dedication and persistence, made a real contribution to marsupial microbiome research that will continue to help wildlife in the future.
Angela Russell does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
New Zealand consistently ranks well in global monitors of democracy, media freedom and open government. But high rates of abuse and threats directed at journalists put us at risk of “mob censorship” – citizen vigilantism that seeks to discipline journalism.
Our recently published study documents newsworkers’ experiences of abuse and violence at New Zealand’s largest news organisation, Stuff.
The research reveals just how widespread online and physical abuse towards journalists has become – and how this is changing the news and who is covering it.
A ‘festering heap of toxicity’
Not one of the 128 journalists and visual journalists surveyed was untouched by abuse, threats or violence related to their job, most commonly delivered via work email on a daily or weekly basis. One respondent described her inbox as a “festering heap of toxicity”.
Women journalists bear the brunt of online abuse, primarily related to their gender or ethnicity (53%) and physical appearance (32%) (such as “ugly bitch” or “Pakeha ugly c***”), compared with 20% of men.
Attempts to discredit them were also reported by 45% of women as opposed to 34% of men. All threats of sexual violence captured in our survey were made towards women.
Overall, men tended to experience more “offline” threats (44% compared to 23% of women) and actual physical violence (16% men compared to 12% women). Nearly 40% of all those experiencing physical violence were visual journalists, showing up to photograph emotionally-charged events such as accidents and protests.
When we further analysed our findings by ethnicity, it was our small subset of Māori women who reported the very highest rates of offline threats and actual violence. These journalists represented the intersection of both gender and ethnicity – increasing their likelihood of being a target of abuse.
Targets for writing about race
As well as capturing the high levels of abuse and threats directed at Māori women journalists, our survey documented ways in which the content of news itself was at risk from mob censorship.
Simply writing stories about race or racism triggered abuse for the writer, whatever their actual or perceived identity.
A self-described “white-passing Māori” explained how, after reporting on the dawn raid apology, she received messages calling her things like “white apologist bitch”. Several Pākeha women were abused as racists or traitors for using te reo Māori in stories or writing about racism.
While a handful of male journalists reported abuse in the vein of “pale, stale, male” – an equally unhelpful development – it was much more common for male respondents to observe greater levels of abuse directed at female colleagues for writing similar stories.
Extensive and detailed reports of gendered abuse provide clear evidence that simply being female puts women journalists at risk in New Zealand, as it does elsewhere.
One participant wrote that “comments about being female are pretty much the common thread of all toxic messages I’ve received” – a pattern that Stuff journalist Michelle Duff has argued was “designed to silence”.
Several women said they turn down opportunities to write opinion pieces. As one said, “I just cannot believe the feedback women get if you express any opinion”.
Similar patterns have been documented by journalist Charlotte Graham McLay. Unsurprisingly, a good proportion of women journalists (22%) contemplated leaving the profession, compared to 4% of men.
But abuse affects all journalists, at least indirectly. Some 71% of our participants adjusted their online behaviours, including closing social media accounts, and 24% indicated they had consciously altered a story. As one person said, “there are [controversial or divisive] stories I’d be less likely to pursue”, including to protect vulnerable sources.
Accepting abuse is not the answer
More than three-quarters of our respondents considered abuse and threats to be just part of the job. There was, though, concern this feeds a “dangerous” and “outdated” professional culture that shuts down frank discussion and causes anxiety.
One female reporter who had experienced on-the-job violence wrote of being “extremely worried” that she or a colleague “will eventually be singled out by an extremist to be attacked or killed”.
Some journalists in our study saw value in responding to abusive emails from readers. As one respondent said, “once I engage with someone (generally) they are apologetic and start interacting like a normal human being”, and exchanges “have morphed into positive experiences for both parties”.
But this emotional labour is an additional burden in under-resourced newsrooms.
Furthermore, some participants were sceptical about the extent of employer commitment to addressing the problem, given the adoption of branding practices such as publishing photo bylines and email addresses, which tended to ramp up online abuse.
Muted watchdogs
Globally, the news industry hasn’t done a good job of training, supporting and protecting its journalists in the digital era.
Research from the United States suggests that receiving regular abuse entrenches journalists’ “us versus them” mentality. This deepens the rift between news organisations and the communities they serve, fuelling mistrust.
Clearly, democracy itself is undermined by any intimidation or disincentive that stops journalists from performing their watchdog duties.
Supporting journalists to do their jobs as safely and free from abuse as possible needs to be the industry’s top priority for 2024. It’s vital not only for them, but also for our democratic future.
This article was written with the assistance of Dr. Catherine Strong, a consultant journalism educator and former journalist. Strong is editor of the American academic journal Teaching Journalism & Mass Communication.
Susan Fountaine does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Tattoo inks are deposited in the layer of skin called the dermis. This layer contains sweat and oil glands, a blood supply, immune cells, collagen to support the skin’s structures, and fibroblasts, which produce collagen.
Fibroblasts take up the ink particles, as do immune cells in the dermal tissue known as macrophages. The ink particles also stick inside bundles of collagen.
Between these three mechanisms, the dermis holds tattoo inks so well they can be seen even on the 5,300-year-old ice mummy Ötzi.
No, and many tattoo artists will not do it. During sunburn, your skin calls in extra immune cells and fluid to kill off and break down cells that have too much UV damage.
This inflammation can affect the tattoo ink deposits. You might not get the look you were after, with too much ink removed by your immune cells or swelling distorting the lines.
It’s much better to be proactive about sun protection before a tattoo, or at least be patient and reschedule when your skin has healed.
How soon after my new tattoo can I go into the sun?
There’s not much research on how soon you can expose your new tattoo to the sun. However, most tattooists advise you to avoid sun exposure while the tattoo heals, generally about three weeks.
This seems sensible, as your fresh tattoo is a type of wound.
Because the skin is damaged by inserting a needle, it’s not too surprising that the most common short-term complication is local inflammation with swelling, redness and discomfort at the tattoo site. There is an influx of immune cells to deal with the damage, much like a sunburn.
So, in one way, you should treat your new tattoo like sunburn and avoid sun exposure while it heals.
But you shouldn’t use sunscreen on the tattoo in that time. That’s because sunscreen can enter the dermis through the puncture wounds and cause more irritation. Cover your new tattoo with loose clothing instead.
Sunlight-induced reactions to both new and existing tattoos are common. There’s usually swelling, itching or stinging on the tattoo site that can start immediately or develop over the course of a day. We’re not really sure why this happens.
Most of the time, these reactions are unpleasant but don’t require medical treatment, much like sunburn.
There is also a small amount of evidence that sunburn on a tattoo temporarily suppresses the skin’s immune system, allowing an infection to become established.
Some ink components, such as mercury or carbon black, are suspected cancer-causing agents when used in other applications. However, there’s no evidence skin cancers are more likely in tattooed skin.
Tattoos make newly-developed skin cancers more difficult to detect. Besides making the lesion more difficult to spot in the first place, the colours of the tattoo interfere with your doctor’s assessment of the colours in the lesion, which can be an important sign of cancer.
So it’s a good idea to get familiar with the moles and freckles on a patch of skin before you’re inked, and check them yourself once a month for changes.
Don’t use sunscreen on new tattoos but after about three weeks, go for it. Pixel-Shot/Shutterstock
Red tattoos seem to be more prone to large but benign (non-cancerous) skin tumours called keratoacanthomas. These appear within a few months of tattooing, and often grow rapidly but then heal by themselves.
However, they can be difficult to distinguish from squamous cell carcinomas (a type of skin cancer). They can also damage underlying structures, such as nerves and muscles. So they often need to be removed anyway.
As tattoos age, they can fade a bit as some of the loose ink particles filter deeper into the dermis. Sun exposure can also degrade ink particles.
There’s limited research on this in human skin. After all, most people don’t want to fade their tattoos for science. So most of what we know is from research in mice.
However, modern tattoo inks give you a strong colour. So in practice, you might not notice any fading for years.
Does tattooed skin sweat differently to un-inked skin?
This is an important question, because sweating is a major way our body avoids overheating in the summer. If you’ve got a full sleeve or your whole back is your canvas, that’s a significant amount of skin.
Since tattooing punctures the skin repeatedly, sweat glands in the dermis may be damaged.
But the research on tattoos’ impact on sweating is mixed and depends on what you are doing at the time.
In one study, researchers used a heatable suit to increase study participants’ internal body temperature by 1°C. Tattooed areas produced about 15% less sweat. It’s not clear if this is enough to increase the risk of heat stress.
However, when other researchers looked at sweating induced by exercise there was no effect in the volume of sweat between tattooed and un-tattooed skin.
When performed under the clean conditions of a licenced tattoo parlour, tattooing is relatively safe.
But long term, some people develop allergic reactions to certain colours due to the different compounds in each, most commonly red dyes. This can cause lumps, scales, scarring or other visible changes.
So, what’s the most common long-term side effect of tattoos? Tattoo regret and wanting to have them removed.
Katie Lee receives funding from the National Health and Medical Research Council.
Erin McMeniman does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
When was the last time you saw a frog? Perhaps you came across one in your garden and wondered at its little hands, glossy skin and what looked very much like a contented smile.
Maybe you regularly see them on Instagram or TikTok, where “frog accounts” have proliferated in recent years. People share adorable cartoon frogs, coo over crocheted frogs or go gaga for frogs dressed in cute hats.
In fact, our fascination with frogs isn’t new. As our research has found, the history of human-frog relations is long and complicated – and not all of it is nice.
There is a rich history of people really loving frogs.
This is interesting, because many people much prefer mammals and birds over reptiles and amphibians.
But the frog is an exception – for a lot of reasons. People tend to be attracted to baby-like faces. Many species of frog have the large eyes characteristic of young animals, humans included.
Having no teeth and no sharp claws, they also do not seem to be immediately threatening, while many of them have beautiful skin colouring and some are improbably tiny.
Frogs are truly among the jewels of the natural world, unlike toads which – with their more mundane colours and “warty skins” – do not usually inspire the same sense of enchantment.
Their beauty connects us to the wider riches of a vibrant nature hidden from most people’s sight in the dense rainforests of the tropical regions.
And they also connect us to nature in our own backyards. At certain times of the year, they spontaneously appear in our gardens and ponds. They can feel like special visitors from the natural world.
Dissecting human feelings for frogs
Yet relationships between people and frogs haven’t always been so positive. In fact, frogs occupy complicated places across cultures all over the world.
In the Western tradition, the legacy of biblical and classical sources was both negative and longstanding.
References to frogs in the Bible rendered them the instrument of divine anger as a swarming plague.
Frogs challenged early modern zoological taxonomies, moving between classification as serpent, insect or reptile.
Perhaps their resistance to easy placement by humans explains the strong emotional language about them used by Swedish naturalist (and “father of modern taxonomy”) Carl Linnaeus.
These foul and loathsome animals are abhorrent because of their cold body, pale colour, cartilaginous skeleton, filthy skin, fierce aspect, calculating eye, offensive smell, harsh voice, squalid habitation, and terrible venom.
In modern science, they sit in a branch of zoology, herpetology, that brings frogs together as “creeping animals” with snakes and lizards.
Frogs have also (or perhaps consequently) suffered in the service of science since at least the eighteenth century because it seemed to be possible to easily replicate experiments across multiple frog specimens.
Frogs were particularly crucial to the study of muscles and nerves. This led to ever more violent encounters between experimenters and frog bodies. Italian scientist Luigi Galvani, for example, did experiments in the late 18th century on legs of frogs to investigate what he thought of as “animal electricity”.
Scientist Luigi Galvani’s 18th-century diagrams of dissected frog legs and various metallic apparatus he used to measure what was thought to be electricity flowing in animals. Library of Congress
In this sense, frogs were valued as significant scientific objects, their value lying in their flesh, their nervous systems, rather than in their status as living, feeling beings in the world.
In time, experiments with frogs moved beyond the laboratory into the classroom. In the 1930s, schoolchildren were expected to find frogs and bring them to school for dissection in biology classes.
This practice was, however, somewhat controversial, with opponents expressing sentimental attachment to frogs and concerns that such animal cruelty would lead to barbarism.
Recognising the fragility of frogs
So, our relationship with frogs is complicated. From the frogs of Aesop’s Fables to the meme Pepe the Frog, we have projected our own feelings and frustrations onto frogs, and exploited them for science and education.
Frogs have also borne the brunt of our failures as environmental stewards.
Climate change is also making life hard for many species. In 2022, over 40% of amphibian species (of which frogs and toads are by far the largest group) were threatened with extinction. Their vulnerability has seen the frog – especially the red-eyed tree frog – become a symbol for the environment more generally.
So we should delight in frogs and marvel at how beautiful and special they are while we still can, and consider how we might help save them.
Something to reflect on next time you are lucky enough to spot a frog.
Susan Broomhall receives funding from the Australian Research Council.
Andrea Gaynor receives funding from the Australian Research Council.
Andy Flack does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
As any frequent social media user knows, airline passengers often record and post in-flight incidents – from frightening turbulence to unruly members of the public.
Often, these viral videos feature flight attendants just trying to do their duties, while being filmed without their consent.
These videos usually portray flight attendants either as heroes effortlessly managing difficult passengers or “villains” accused of being rude and unprofessional. Either way, the trend is emerging as an industrial issue, with unions arcing up about it and airlines bringing in new rules aimed at curbing the practice.
Going to work knowing that at any moment you may become the unwilling star of a viral video can exact a considerable toll on the wellbeing of flight attendants.
I (Liz Simmons) speak daily with flight attendants in Australia and abroad as part of my PhD research. From these discussions, I’ve heard from attendants who worry often about discovering videos of themselves featuring unkind comments about their appearance, age or employer.
One flight attendant, Kate*, described the disconcerting feeling of someone aiming a smartphone camera at her while she was simply trying to do her job, saying:
You don’t know why they’re filming or what they’ll do with it.
Marie spoke of being featured in a TikTok video during a safety demonstration, with viewers making fun of her appearance.
Charlotte, after refusing to serve more alcohol to an intoxicated passenger, had a camera thrust in her face, accompanied by threats to her job.
Mark told of how uncomfortable he felt having to ask a passenger to stop taking photos of the crew during service.
These personal accounts illustrate the distress flight attendants can experience when being filmed or photographed without their knowledge.
Imagine going to work knowing that, at any moment, you may become the unwilling star of a viral video. Shutterstock
A broader industrial issue
This issue is drawing the attention of policymakers, airlines and the unions that represent flight attendants.
Japan recently introduced laws aimed at curbing sneak photography in a range of settings, which may be used to prevent passengers voyeuristically filming flight attendants. Research by Japan’s aviation workers union found that about 70% of the 1,573 flight attendants surveyed believed they’d had their pictures taken surreptitiously while they were working.
Passengers have been arrested in Turkey and India after unauthorised filming.
And flight attendant unions in Japan, Hong Kong and Australia have voiced concerns about the issue.
Of course, videos can occasionally play a crucial role in understanding what transpired during an in-flight incident, and flight attendants themselves can also be found on social media sharing their stories, consenting to the video. But many videos still feature airline staff simply going about their job (while being filmed, without their consent).
Unclear rules
News reports suggest staff aboard Dutch carrier KLM “now commonly make an announcement during the safety briefing asking passengers not to take photos of any crew members.”
The rules on the KLM website are less clear, saying only that
Recording videos and/or taking photographs other than personal videos and photographs is prohibited on board the aircraft.
Virgin Australia’s rules state anyone travelling on their planes must
use cameras or photographic devices (including mobile phones) for personal use only. You must comply with the directions of flight crew when using cameras or photographic devices while on board.
In November 2023, Qantas introduced new rules requiring passengers to
seek consent before filming or photographing Qantas Group staff, contractors or other customers.
This is a start. For most airlines, however, there is a notable absence of clear guidelines against recording and publishing footage of flight attendants in their workplace. The existing rules are often buried in the fine print of terms and conditions, which few passengers take the time to read. This underscores the necessity for airlines to reconsider how these restrictions are communicated to passengers.
Looking ahead, it may be timely for more airlines to establish clearer rules on filming cabin crew while they work. There should be an acknowledgement that unsolicited filming is frequently unfair, invasive and distressing. Developing a framework to enforce these provisions and enhancing communication about these rules would help inform passengers about how to respect the privacy and comfort of flight attendants in their workplace.
* All names have been changed to protect identities.
Liz Simmons is a member of the Griffith Institute For Tourism (GIFT), and a member of the Australian Aviation Psychology Association (AAvPA). She was an Australian-based cabin crew from 2004-2021, and during that time was a financial member of the Flight Attendant’s Association of Australia (FAAA).
Rawan Nimri is a current member of the Griffith Institute For Tourism (GIFT).
Gui Lohmann does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
In our house we have a favourite story about the time our toddler was dragged from the National Portrait Gallery kicking and screaming “I want to see more paintings!!!”
She needed lunch, we had to go, but she really loved the “Nick Cave Gallery”, as she called it, with his luminous portrait by Howard Arkley on display.
What parenting miracle did we pull off to have a daughter that loves art galleries so much? We have always taken our kids to galleries. It’s what we do for fun and is what they want to do as teenagers. Visiting a new town or city, we check out local art wherever we can find it.
I have a long history of working with galleries and I am a practising artist, so gallery spaces are familiar to us and are meaningful places associated with joy, wonder and celebration. But you don’t need to be an artist to help your kids enjoy a gallery visit.
Children are naturally curious, so start young and make gallery visits a normal activity.
Expose babies to art as soon as possible: research proves regular engagement with art develops children’s aesthetic sensibilities and even very young children can respond to art in complex ways.
Even very young children can respond to art in complex ways. Shutterstock
I remember my baby son neighing like a horse in front of a painting before he could talk. I looked at the painting he was staring at, Nicholas Harding’s Bob’s daily swim. There in the thick, painterly background, was a horse. My son connected with the work because he loved horses.
Before your visit
Look for ways to introduce your child to artists before your visit. Art activities bring exhibits to life in fun and engaging ways.
Try to tap into your child’s interests. If they like superheroes, pop icons or Hollywood stars they might just love to see a show by Yankunytjatjara artist Kaylene Whiskey.
Marilyn JS Goodman’s brilliant book Children Draw includes tips on taking your child to a gallery: consider going on a weekday when it’s less crowded, include the cafe, and, importantly, don’t try to see everything – for younger children plan on spending no more than an hour and don’t try to look at too many art works.
Making visiting a gallery a normal part of life. Shutterstock
Let your child take the lead and include them in the planning. Planning a trip together may be the perfect time to ask questions and share knowledge: “did you know we can’t touch artwork in galleries? Do you know why?”
This can not only help avoid awkward situations with security guards but also helps your child to understand why we don’t touch art (we need to protect the artworks), and may encourage further inquiry into the art or gallery.
There’s no right or wrong response
Some adults may feel uncomfortable talking about art. Just try having a conversation about what you see, and be prepared to be amazed by what your child observes.
Start by asking your child questions: what are you noticing about this exhibition? What stories are these works telling? What do you think about when you look at this artwork?
Ask questions like ‘what does it make you wonder?’ Shutterstock
In schools, you might hear teachers use thinking routines: what do you see? What do you think about that? What does it make you wonder? This stimulates curiosity and encourages students to make careful observations and thoughtful interpretations.
Some galleries use Visual Thinking Strategies, which also consists of three questions: what’s going on in this picture? What makes you say that? What else can we find?
You don’t have to like what you see. This can even be a great stimulus for discussions with your child: does art have to be beautiful to be good? Why do people make art? What was that exhibition about?
Interact with the art
You are allowed to take pencil and paper into most galleries and drawing is a great way of looking and slowing down your experience.
Most galleries have seating where you can sit and draw. Try taking a sketchbook for you and one for your child. Role model drawing, taking your time. You are not aiming to make a masterpiece but to use drawing to map out what you see.
Compare drawings and swap notes. Ask your child what they noticed and share what you found.
Another fun game in a gallery is to pose like the sculptures and paintings.
Most galleries offer programs for children and families. By attending tours you can pick up excellent tips from the educators who are experts at engaging children. They use simple and effective methods such as rolling a piece of paper up into a telescope to look at a work.
Most galleries offer programs for children and families. Shutterstock
Some galleries also have children’s trails especially designed for engaging children. And if they don’t, you can make things up like how many trees can you see? Or can you find any animals in this exhibition?
After the visit
In a previous article I talked about extending your child’s experience after a gallery visit and how a comic my son made gave me an insight into his feeling about what he had seen at the gallery.
Make it a special day out together. At the end of the day you want your child to enjoy the experience and foster a love of art.
Naomi Zouwer does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
It’s accepted wisdom that oil and water don’t mix. The water and oil molecules have distinct chemical properties that don’t interact well together.
You may have seen this if you’ve attempted to make a salad dressing by shaking together oil and vinegar (which is mostly water), which gives a temporary suspension that quickly separates.
There is a large energy cost to breaking apart and mixing the water and oil layers. The secret to blending them together is to add an extra ingredient known as a “surfactant” or emulsifier.
The name surfactant is derived from “surface active”. It highlights that these molecules work at the surface or interface to bridge the interactions between the oil and water. This is similar to how detergents are able to remove grease from your dishes.
Many vinaigrette recipes call for emulsifiers without specifically mentioning their crucial emulsifying role.
Key examples are mustard and garlic, which contain “mucilage” – a mix of carbohydrates – that can act as emulsifiers.
So if your vinegar/oil salad dressings are separating, make sure you’re adding enough of these ingredients (which also contain wonderful flavour chemicals).
Many vinaigrette recipes call for emulsifiers such as mustard. Shutterstock
Commercial salad dressings also contain naturally sourced emulsifying carbohydrates. These will often be listed on the ingredients as generic “vegetable gum” or similar, and you may need to read the label and delve a little deeper into the food additive number to find out the source.
Researchers have raised questions about synthetic emulsifiers used in processed food, as studies in mice suggest they have health risks. It’s too early to say exactly what this means for humans.
Shake it ‘til you make it
Mixing is key to dispersing oil in water. While shaking a jar is convenient, a whisk or food processor will give a more complete emulsion. The white (or opaque) colour of many emulsions is due to the formation of microdroplets that scatter light.
These mechanical mixing methods are even more essential for the formation of so-called “permanent emulsions” such as mayonnaise.
Mayonnaise is an emulsion of oil in water, but egg yolk is the key emulsifier. Egg yolks contain long molecules called phospholipids that are able to interact with both the oil layer and the water. Mayonnaise is an impressively stable emulsion, which is why is can be sold in a shelf-stable form.
But it isn’t infinitely stable; heating the mayonnaise emulsion will cause it to split. Perhaps you’ve hurriedly prepared a potato salad and added a mayonnaise-based dressing before the potatoes have cooled down?
Or toasted a sandwich spread with mayonnaise? (Incidentally, adding mayonnaise to the outside of a toasted sandwich is an excellent path to some delicious and crispy chemical reactions.)
The heat destabilises the emulsion and the separate oil and water phases will reform. Depending on the mixture, split emulsions may be recovered by adding more emulsifier and re-whisking or re-mixing.
Hollandaise sauce is a notoriously difficult emulsion to prepare. The traditional hollandaise method involves whisking egg yolk, water, and lemon juice over a low heat, then slowly adding melted butter with further whisking. Not only can the emulsion split, but you can also overcook the added emulsifying egg yolk.
The key to a successful hollandaise emulsion is separating the butter into fine, dispersed droplets, giving a thick and opaque mixture, but without cooking the eggs. Adding the butter too quickly or without sufficient mixing can give a split sauce.
Using an immersion blender can help, as can controlling the temperature of the melted butter. You might get a more consistently emulsified sauce with far less strain on your wrists.
Mechanical mixing methods are even more essential for the formation of ‘permanent emulsions’ such as mayonnaise. Shutterstock
You’ve got me feeling emulsions
Emulsions are used in many more places than salads and sauces. Most medicated creams, cosmetics and lotions are emulsions of oils and water, which is why they look white.
Gardeners might be familiar with a mixture known as “white oil” – a mixture of vegetable oil and detergent. This brew, when diluted in water, is an inexpensive, effective, yet mild insecticide. Commercial versions often contain other pesticides, so make sure you read the label.
Modern acrylic paints use emulsions for both their manufacturing and application. The emulsions suspend the paint polymers in a water base.
The water from the paint evaporates, leaving a film of paint polymers that can’t be re-dispersed into water. This clever chemical trick has saved huge quantities of oil-derived solvents from being used, inhaled, and emitted into the environment from traditional oil-based paints.
So next time you’re making a salad, check your emulsions. Opposites don’t attract, but mixing them with the right chemistry can give a delicious result.
Nathan Kilah does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
As you’re driving around this summer holidays, there’s every chance you’ll see a strange-looking white or yellow box on the side of the road.
It might have cameras protruding overhead, or be emblazoned with road safety slogans.
It’s a mobile road safety camera. It’ll catch you out doing everything from speeding, to using your phone while driving, to failing to wear a seat belt.
So how did these cameras come about, and how do they work?
In Australia, around 1,200 people die in car crashes every year.
The number of people seriously injured has risen from 34,000 in 2011 to around 39,000 in 2019 (although this may partly be explained by changes in the way admissions to hospital are reported).
Alarmingly, these numbers are showing no sign of decline.
It is widely recognised that behaviours such as speeding, drink or drug driving, fatigue, distraction and dangerous driving increase the risk of a crash.
Failing to wear a seat belt can lead to more severe injuries when a crash occurs.
To reduce the trauma on our roads caused by these behaviours, we need to increase compliance with the road rules and encourage safer driving. The use of safety cameras for enforcement has become a crucial part of the road safety response.
A short history of safety cameras
Safety cameras were first used in Australia in 1985 with the introduction of speed cameras in Victoria.
Since then, the use of safety cameras has grown to include fixed red light and speed cameras, mobile speed cameras (that can be moved to different locations), and point-to-point cameras (also known as average speed cameras).
In the past three years, mobile phone detection cameras have been introduced in New South Wales, Queensland, Victoria, the ACT and Tasmania, and will soon be operating in South Australia. They have also been trialled in Western Australia.
Currently, Queensland and Tasmania are the only states to also use these cameras for seat belt enforcement, although NSW intends to do so in 2024.
Safety cameras, whether looking at speed or other dangerous driving behaviours, can be either fixed or mobile.
Fixed cameras are permanently located at one spot and operate around the clock. They have primarily been used to target speeding and red light running.
Mobile cameras, those roadside trailers you might see, can be moved from one location to another and can be deployed virtually anywhere at any time. They are mainly used to target speeding and can also be mounted on a vehicle or tripod.
Trailer-based safety cameras can be left unattended in place for longer periods and are usually equipped with security devices such as alarms and security cameras. They also have a secure housing (that’s sometimes bulletproof) to protect against tampering and vandalism.
Typically, they’re placed in areas with a history of crashes or where speeding, distraction, restraint use, or safety are of concern.
So how do they actually work?
Safety cameras use radar or laser to detect and measure vehicle speeds. Sensors embedded in the road are used to detect red light running.
Depending on how they are set up, safety cameras can monitor multiple vehicles across multiple lanes and approaching from opposite directions.
They use high-definition cameras that are effective in different lighting and weather conditions, including night, fog and heavy rain. Some are able to identify and enforce speed limits for different types of vehicles (like heavy vehicles).
They may also use automated number plate recognition capabilities that allow them to detect or identify so-called “hot list” vehicles that are of interest to police (stolen, unregistered, unlicensed owners, for example).
Fixed and mobile cameras enforce speeds in their immediate vicinity, while point-to-point cameras measure the average speed of vehicles between two points and as vehicles pass the camera locations at the beginning and end of the zone. Currently point-to-point enforcement is fixed, but it is likely that portable cameras will also be used in the future.
Mobile phone detection cameras make use of high-definition cameras and infrared lighting that allow them to see through the windscreen and determine when someone is illegally using a mobile phone. They can also determine whether they are wearing their seat belt correctly.
These cameras can also measure vehicle speed and use number plate recognition to monitor vehicles. It means they can help enforce pretty much everything. They can be either fixed or mobile.
Do they work to improve driver behaviour?
Research indicates safety cameras do just what the label implies: improve safety.
A systematic review of the effects of different types of speed cameras suggests they are effective at reducing average speeds and the number of vehicles speeding, and, more importantly, reduce serious injury and fatal crashes by around 20% each.
Studies examining the effectiveness of mobile phone cameras are yet to be undertaken. However, NSW experienced a substantial decline in mobile phone use in the three years following their introduction.
End-of-year results aren’t only for school and university students. Countries, too, can be measured for their progress – or lack of it – across numerous categories and subject areas.
This report card provides a snapshot of how New Zealand has fared in 2023. Given the change of government, it will be a useful benchmark for future progress reports. (Somewhat appropriately, the coalition seems keen on standardised testing in education.)
It’s important to remember that this exercise is for fun and debate. International and domestic indices and rankings should be read with a degree of caution – measurements, metrics and numbers from 2023 tell us only so much.
Nevertheless, it’s still possible to trace the nation’s ups and downs. As the year draws to an end, we can use these statistics and rankings to decide whether New Zealand really is the best country in the world – or whether we need to make some additional new year’s resolutions.
International pass marks
Overall, the country held its own internationally when it came to democratic values, freedoms and standards. But there was a little slippage.
Despite falling a spot, Transparency International ranked New Zealand second-equal (next to Finland) for being relatively corruption-free.
In the Global Peace Index, New Zealand dropped two places, now fourth-best for safety and security, low domestic and international conflict, and degree of militarisation.
The country held its ground in two categories. Freedom House underlined New Zealand’s near-perfect score of 99 out of 100 for political and civil liberties – but three Scandinavian countries scored a perfect 100. The Global Gender Gap Report recorded New Zealand as steady, the fourth-most-gender-equal country.
Supplementary work by the United Nations Development Programme shows New Zealand making impressive strides in breaking down gender bias.
The Index for Economic Freedom, which covers everything from property rights to financial freedom, again placed New Zealand fifth, but our grade average is falling. We also dropped a place in the World Justice Project’s Rule of Law Index to eighth.
New Zealanders are about as happy as they were last year, still the tenth-most-cheery nation, according to the World Happiness Report.
The Human Development Index did not report this year (New Zealand was 13th in 2022). But the Legatum Prosperity Index, another broad measure covering everything from social capital to living conditions, put New Zealand tenth overall – reflecting a slow decline from seventh in 2011.
The Economist’s Global Liveability Index has Auckland at equal tenth, with Wellington racing up the charts to 23rd. (Hamilton, my home, is yet to register.)
While New Zealand registered a gradual slide in the Reporters Without Borders Press Freedom Index, at 13th position it still ranks highly by comparison with other nations.
Could do better
New Zealand has seen some progress around assessment of terror risk. While the national terror threat level has remained at “low”, the Global Terrorism Index ranked the country 46th – lower than the US, UK and Russia, but higher than Australia at 69th.
On the Global Innovation Index, we came in 27th out of 132 economies – three spots worse than last year. The Globalisation Index, which looks at economic, social and political contexts, ranks New Zealand only 42nd.
But the country’s response to climate change is still considered “highly insufficient” by the Climate Action Tracker, which measures progress on meeting agreed global warming targets. The Climate Change Performance Index is a little more generous, pegging New Zealand at 34th, still down one spot on last year.
New Zealand’s overseas development assistance – low as a percentage of GDP compared to other OECD countries – had mixed reviews.
The Principled Aid Index – which looks at the purposes of aid for global co-operation, public spiritedness and addressing critical development goals – ranks New Zealand a lowly 22 out of 29.
The Commitment to Development Index, which measures aid as well as other policies (from health to trade) of 40 of the world’s most powerful countries, has New Zealand in 19th place.
median weekly earnings from wages and salaries continued to rise, by NZ$84 (7.1%) to $1,273 in the year to June
inflation is rising, but the rate is slowing, falling to 5.6% in the 12 months to September
and good or bad news according to one’s perspective, annual house price growth appears to be slowly recovering, with the average price now $907,387 – still considerably down from the peak at the turn of 2022.
It’s worth noting, too, that record net migration gain is boosting economic measurements. In the year to October 2023, 245,600 people arrived, with 116,700 departing, for an annual net gain of 128,900 people.
In the year to June, recorded suicides increased to 565, or 10.6 people per 100,000. While an increase from 10.2 in 2022, this is still lower than the average rate over the past 14 years.
Incarceration rates began to rise again, climbing to 8,893 by the end of September, moving back towards the 10,000 figure from 2020.
Child poverty appears to be stabilising, with some reports suggesting improvements in longer-term trends. While commendable, this needs to be seen in perspective: one in ten children still live in households experiencing material hardship.
The stock of public housing continues to increase. As of October, there were 80,211 public houses, an increase of 3,940 from June 2022.
In short, New Zealand retains some bragging rights in important areas and is making modest progress in others, but that’s far from the whole picture. The final verdict has to be: a satisfactory to good effort, but considerable room for improvement.
Alexander Gillespie does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
At this time of year many of us resolve to prioritise our health. So it is no surprise there’s a roaring trade of products purporting to guarantee you live longer, be healthier and look more youthful.
While an estimated 25% of longevity is determined by our genes, the rest is determined by what we do, day to day.
There are no quick fixes or short cuts to living longer and healthier lives, but the science is clear on the key principles. Here are five things you can do to extend your lifespan and improve your health.
What you eat has a huge impact on your health. The evidence overwhelmingly shows eating a diet high in plant-based foods is associated with health and longevity.
If you eat more plant-based foods and less meat, processed foods, sugar and salt, you reduce your risk of a range of illnesses that shorten our lives, including heart disease and cancer.
The Mediterranean diet is one of the healthiest and most studied eating patterns. Louis Hansel/Unsplash
Plant-based foods are rich in nutrients, phytochemicals, antioxidants and fibre. They’re also anti-inflammatory. All of this protects against damage to our cells as we age, which helps prevent disease.
No particular diet is right for everyone but one of the most studied and healthiest is the Mediterranean diet. It’s based on the eating patterns of people who live in countries around the Mediterranean Sea and emphases vegetables, fruits, wholegrains, legumes, nuts and seeds, fish and seafood, and olive oil.
2. Aim for a healthy weight
Another important way you can be healthier is to try and achieve a healthy weight, as obesity increases the risk of a number of health problems that shorten our lives.
Obesity puts strain on all of our body systems and has a whole myriad of physiological effects including causing inflammation and hormonal disturbances. These increase your chances of a number of diseases, including heart disease, stroke, high blood pressure, diabetes and a number of cancers.
In addition to affecting us physically, obesity is also associated with poorer psychological health. It’s linked to depression, low self-esteem and stress.
One of the biggest challenges we face in the developed world is that we live in an environment that promotes obesity. The ubiquitous marketing and the easy availability of high-calorie foods our bodies are hard-wired to crave mean it’s easy to consume too many calories.
3. Exercise regularly
We all know that exercise is good for us – the most common resolution we make this time of year is to do more exercise and to get fitter. Regular exercise protects against chronic illness, lowers your stress and improves your mental health.
While one of the ways exercising helps you is by supporting you to control your weight and lowering your body fat levels, the effects are broader and include improving your glucose (blood sugar) use, lowering your blood pressure, reducing inflammation and improving blood flow and heart function.
While it’s easy to get caught up in all of the hype about different exercise strategies, the evidence suggests that any way you can include physical activity in your day has health benefits. You don’t have to run marathons or go to the gym for hours every day. Build movement into your day in any way that you can and do things that you enjoy.
If you want to be healthier and live longer then don’t smoke or vape.
Smoking cigarettes affects almost every organ in the body and is associated with both a shorter and lower quality of life. There is no safe level of smoking – every cigarette increases your chances of developing a range of cancers, heart disease and diabetes.
Even if you have been smoking for years, by giving up smoking at any age you can experience health benefits almost immediately, and you can reverse many of the harmful effects of smoking.
If you’re thinking of switching to vapes as a healthy long term option, think again. The long term health effects of vaping are not fully understood and they come with their own health risks.
When we talk about living healthier and longer, we tend to focus on what we do to our physical bodies. But one of the most important discoveries over the past decade has been the recognition of the importance of spiritual and psychological health.
People who are lonely and socially isolated have a much higher risk of dying early and are more likely to suffer from heart disease, stroke, dementia as well as anxiety and depression.
Although we don’t fully understand the mechanisms, it’s likely due to both behavioural and biological factors. While people who are more socially connected are more likely to engage in healthy behaviours, there also seems to be a more direct physiological effect of loneliness on the body.
So if you want to be healthier and live longer, build and maintain your connections to others.
Hassan Vally does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
As each day passes, the need to protect Australia’s environment grows more urgent. As noted in the most recent State of Environment Report in 2021, we are increasingly turning to “measures of last resort” to prevent species extinctions and the collapse of ecosystems.
Around the globe, lawyers and policy makers have been engaged in finding ways the law can contribute to the protection of ecosystems. Conferring ecosystems with rights is one strategy we can use to prevent species extinctions and ensure a “voice” for nature.
Central to these efforts has been realising the rights of nature based on legal personhood, which confers entitlements and duties on an entity. There are benefits, complexities and risks involved in this approach.
Indeed, the use of legal personhood as a mechanism to give natural entities like rivers or wetlands rights has been criticised from a First Nations perspective.
At a time when we are seeing threats to the environment turn into catastrophes with alarming frequency, the law can be an inflexible tool and slow to respond.
In Australia, the rights of nature idea is emerging in social and political debate. Ultimately, the success of the rights of nature vision depends on effective broad legal frameworks combined with local action.
Sometimes, we can overlook the significant role local-level reform can play. So it is encouraging to see communities and councils leading the way.
The rights of nature principle provides a framework a local community can use when wanting to show its respect for nature and ensure due care for the local ecosystem.
Two examples of local governance
Two examples of such local leadership are the Blue Mountains City Council in NSW and the Shire of Augusta Margaret River local government area in WA.
In rights talk, “intrinsic value” means that a thing or being has value “in itself”, or “for its own sake”.
For example, a tree has intrinsic value for its own sake because it is a living thing and the tree’s life has value in and of itself. The tree’s value is not based on how it can be used by humans.
With some exceptions, Western philosophers have confined intrinsic value to human beings alone. The same notion permeates the law. Yet recognising the intrinsic value of other species and our broader environment is a pathway to ethical reflection and has the potential to transform our perspective.
In Western Australia, following community advocacy, the Shire of Augusta Margaret River has also shown leadership in this regard. Among other things, the shire’s May 2023 Overarching Sustainability Policy requires due regard for “the needs, rights and wisdom of Traditional Custodians” and “the rights of nature to exist, thrive and evolve”.
We believe these local examples give cause for optimism and a source of “slow hope”. And First Nations leadership sits at the heart of these developments. Community-led approaches are key to caring for Country, something that’s also noted in the latest State of the Environment report.
Best-practice local policy development can actively enable caring for Country and integrate it into the regulatory conversations that inform the operational plans of councils.
For the CSIRO First Nations Australian Peoples led research initiative Our Knowledge, Our Way, connection to Country is a cultural must. For First Nations peoples, Country already has “rights”: to be cared for, respected and listened to. This is a relationship that arises organically and is entwined in the experience of being human.
From a Western perspective, enshrining rights of nature thinking in environmental stewardship at all levels of society is something environmental ethicists describe as essential.
Local communities can draw upon these two convergent lines of thinking to inform culturally sensitive collaboration. While higher levels of government are yet to introduce the principle of rights of nature into legislation, leadership at local levels is showing us it can be done. State and federal governments should take note.
Alexandra McEwan is a member of the Australian Earth Laws Alliance.
Michael Hewson undertook a sabbatical at the Rachel Carson Centre for Environment and Society (Ludwig Maximillian University Munich Deutschland) from September 2022 to February 2023.
Rolf Schlagloth does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Paul J. Maginn, Interim Director, UWA Public Policy Institute; Associate Professor & Programme Co-ordinator (Masters of Public Policy), The University of Western Australia
Paul J. Maginn/@Planographer
Retail activity has been a defining facet of cities since antiquity. The Greek Agora and Roman Forum may be viewed as the original CBDs – central business districts, or what urban planners call activity centres.
Retail spaces have evolved over time. Urbanisation, mass production and the rise of conspicuous consumption led to the high street and CBD dominating the retail landscape across the Western world from the late 19th century until the mid-20th century.
The 21st-century retail landscape has become more diverse and competitive. The range of physical and virtual retail spaces, retailers, products and prices leaves consumers spoilt for choice.
Retailing is more than just about consumption. It’s Australia’s fourth-largest employment sector and plays a major role in shaping our cities. Retail helps define a city’s identity and brand and thus attract visitors. But the retail landscape and consumer behaviour are changing, and changing fast!
In Australia (and elsewhere), the CBD was at the epicentre of the evolution of discrete retail spaces. It offered a smorgasbord of independently owned shops, national and international chain stores and department stores. These were located in laneways, shopping arcades, main streets and multistorey shopping centres.
Centrality, easy public transport access and a largely suburban-based commuter workforce explain the dominance of the CBD in the 20th century.
A visit to the CBD on a Saturday was more than just a utilitarian shopping trip. It could be an urban exploration, a leisure pursuit, a pleasure-seeking adventure, a social event.
Children accompanying their parents were mesmerised by the intensity of urbanism and retail choice. Teenagers and young people, much like 19th-century flaneurs, paraded with their peers, their fashion denoting their subcultural affiliation.
For adults, the CBD offered a chance to indulge in retail therapy via window shopping and pleasurable consumption. For others a trip to the CBD allowed them to treat themselves and meet friends at the department store cafe.
In short, the CBD was the place to see and be seen.
CBD’s retail crown slips
The dominance of the CBD began to slip with the emergence of suburban shopping centres in the late 1950s – thank you, Victor Gruen. Rapid suburban growth, social mobility and increased car use drove an explosion in suburban shopping centres from the 1960s through to the 1980s.
According to the Shopping Centre Council of Australia, an average of 22 shopping centres a year have been built since the first centre, Brisbane’s Chermside, appeared in 1957.
Competition between CBD retailers and shopping centres intensified in the 1980s and 1990s. With the rise of online retailing in the past decade or so, these bricks-and-mortar retailers have had to lift their game again.
Over the same period, online retail spending increased by 132% from $27.5 billion to $63.8 billion. It now accounts for just over 18% of retail spending in Australia, up from 10% in 2018.
The “4 Cs” underpin the rise of online shopping: convenience, choice, competitive prices and COVID-19 (which ramped up the shift).
COVID and working from home led to Australian CBDs, especially Melbourne and Sydney, losing considerable ground, while suburban shopping centres gained in terms of shopper numbers and spending.
Although zombified CBDs at the height of pandemic restrictions are in the rear-view mirror, working from home lingers. This is especially true for Melbourne where office occupancy averages 53% – way behind Perth (91%), Adelaide (85%), Sydney and Brisbane (both 75%).
Actions include everything from free parking and public transport, tactical urbanism or temporary changes to the streetscape such as pedestrian plazas, pop-up bike lanes, and parklets, outdoor dining, public events and vouchers, through to changes in planning regulations to speed up high-density residential development.
Before and since COVID-19 major shopping centres across Australia have undergone multi-million-dollar refurbishments and redesign. They include centres in Adelaide (Marion), Brisbane (Chermside, Pacific Fair), Melbourne (Chadstone, Fountain Gate), Perth (Carousel, Karrinyup) and Sydney (Parramatta, Macquarie Centre). The centres have increased floorspace and diversified retail, entertainment and food and beverage offerings.
Suburban shopping centres are more than cathedrals of consumption. Mega-malls such as Chadstone (215,000m²), Fountain Gate (178,000m²) and Chermside (177,000m²) stand out as major hubs of economic activity and employment, tourist attractions and social and community spaces.
To help secure a ready customer base, upmarket hotels and luxury residential developments have been built, or are earmarked for development, as part of major shopping centres. Many more such residential developments in Australia (and the US) are likely over the next decade or so.
A proposed luxury apartment development, West Village, next to Karrinyup Shopping Centre in Perth, WA. Paul J. Maginn/@Planographer
Devil in the retail
The competition between bricks-and-mortar retailers in CBDs, suburban shopping centres and online retailers peaks each year with the onset of Black Friday and Cyber Monday in late November, closely followed by the Christmas shopping season and New Year sales.
Whatever big changes come next – in terms of what we buy, where and how – will have implications well beyond the retail sector. The structure and function of cities, plus our relationship with the city and retail spaces, are likely to change.
With the rise of online shopping and on-demand delivery, can we, for example, expect to see our streets and skies soon filled with autonomous robots and drones?
Autonomous delivery raises major questions about retail, urban and residential design, infrastructure provision, employment, human behaviour and, ultimately, regulation. Therein lies the devil in the retail.
The authors do not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and have disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By David Rowe, Emeritus Professor of Cultural Research, Institute for Culture and Society, Western Sydney University
As the old year passes and a new one arrives, three notable sport events occupy the languid vacation hours. Melbourne’s Boxing Day and Sydney’s New Year’s Test matches are spliced by the Sydney to Hobart Yacht Race.
Unlike the race, a set-piece seasonal spectacle notable mainly for its Rolex-sponsored affluence, picturesque helicopter shots, and (seemingly) AI-generated reporting, the cricket stirs strong emotions.
Many people are seduced by the nostalgic notion that no Australian summer is complete without two metropolitan Test matches played on green fields. Much of the experience involves half-watched television and part-heard radio broadcasts.
Like many “traditions”, the Boxing Day Test at the Melbourne Cricket Ground (MCG) is quite recent – in fact, barely 40 years old.
It is the product of jet travel, global year-round tour schedules and, especially, the needs of commercial television.
Kerry Packer grasped the lucrative potential of large, captive audiences on vacation. Acquiring the broadcast rights in 1979, he set about maximising their value for Channel Nine. Before then, Boxing Day Tests in Melbourne were intermittent, with three in the 1970s even being staged in Adelaide.
Fairly regular Tests at the Sydney Cricket Ground (SCG) in January and February began in the late 1960s, but it was not until the late 1990s that they settled on the first week of the year. Patriotic television advertisements substantially created this misleading picture of time-honoured festive cricket rituals.
An evolving game with a crowded calendar
In the midst of this orgy of cricketing nostalgia and overindulgence of food and liquid, purists find the mounting threats to the five-day format unpalatable.
It is hard to imagine today that one-day cricket was once regarded as the “fast food” version of the game.
But that was before we got the memo from, in particular, the men’s and women’s Indian Premier League.
Here, players are literally bought and sold in a sporting meat market, along with megabuck franchises. Cricket contests are shrunk to 20-over “big bashes” of barely three hours’ duration, the senses bombarded with music, dance, programmed crowd stimulation and loud advertisements.
This Twenty20 form of the game has mushroomed around the world, including in the sportswashing capitals of the Middle East. It has been joined recently by a newer, fast-paced variation called The Hundred to compete with the slower, longer one-day and Test forms of the game.
After more than a century in the Olympic wilderness, cricket is also returning to the fold at the 2028 Los Angeles Games, courtesy of some heavy lobbying by India. It may well feature at the 2032 Brisbane Games, where its famous venue, the Gabba, will be rebuilt.
Television ads for text cricket in the 1980s were big on patriotism (and jingles).
Consequently, the global cricket calendar is becoming even more congested. A clear case is the Twenty20 series that took place in India within four days of the month-long men’s 2023 World Cup.
The teams that played in the one-day final, Australia and India, faced off again in the Twenty20. But half the Australian team returned home, and only one of the Indian one-day team participated.
Such time pressures and competition variations encourage more players and coaches to specialise in different cricket formats. The money is comparatively easy in the short form of the game, while the physical and mental health toll can be reduced by opting out of Test and even one-day cricket altogether.
Suffering in the name of tradition
The Australian cricketers who do play in future Melbourne and Sydney Tests may find they will move west to Adelaide or Perth, or north to Brisbane. As Cricket Australia goes to tender for its new seven-year broadcast contract, it has made clear that no venue has a guaranteed Test match.
Of course, such matters are being raised in a play for more cash. But with expensive new stadia to fill and state governments offering juicy inducements to snag a prestigious Test match, Australia’s two largest cities may be dismissed on these crucial days.
There is also the problem of the frequently sodden Sydney, with agitation that the key New Year’s Test should be moved from one of the wettest cities where elite cricket is played.
To preserve the heritage value of the New Year’s Test, must bored, damp spectators sit in the stands? Or TV viewers be forced to watch images of a covered pitch and listen to droning fill-in commentary?
As the COVID pandemic lockdown showed, sports like cricket now resemble continuous-process manufacturing industries, or global just-in-time operations where the “product” is assembled via intricate logistics.
The lines between tradition and progress constantly shift in these hyper-commercial cricketing times. One casualty may be the largely illusionary sense of continuity proffered by Australia’s Boxing Day and New Year double bill.
David Rowe ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
As we enter the festive season it’s a good time to think about what all those celebratory alcoholic drinks can do to your gut.
Alcohol can interfere with the time it takes for food to go through your gut (also known as the “transit time”). In particular, it can affect the muscles of the stomach and the small bowel (also known as the small intestine).
So, how and why does alcohol make your poos goes weird? Here’s what you need to know.
Alcohol’s effect on stomach transit time depends on the alcohol concentration.
In general, alcoholic beverages such as whisky and vodka with high alcohol concentrations (above 15%) slow down the movement of food in the stomach.
Beverages with comparatively low alcohol concentrations (such as wine and beer) speed up the movement of food in the stomach.
These changes in gut transit explain why some people can get a sensation of fullness and abdominal discomfort when they drink vodka or whisky.
How long someone has been drinking a lot of alcohol can affect small bowel transit.
Alcohol can affect the time it takes for food to go through your gut. Shutterstock
We know from experiments with rats that chronic use of alcohol accelerates the transit of food through the stomach and small bowel.
This shortened transit time through the small bowel also happens when humans drink a lot of alcohol, and is linked to diarrhoea.
Alcohol can also reduce the absorption of carbohydrates, proteins and fats in the duodenum (the first part of the small bowel).
Alcohol can lead to reduced absorption of xylose (a type of sugar). This means diarrhoea is more likely to occur in drinkers who also consume a lot of sugary foods such as sweets and sweetened juices.
This means chronic alcohol use may lead to diarrhoea and loose stools.
How might a night of heavy drinking affect your poos?
When rats are exposed to high doses of alcohol over a short period of time, it results in small bowel transit delay.
This suggests acute alcohol intake (such as an episode of binge drinking) is more likely to lead to constipation than diarrhoea.
This is backed up by recent research studying the effects of alcohol in 507 university students.
The Bristol Stool Chart classifies poo into different groups. Shutterstock
These students had their stools collected and analysed, and were asked to fill out a stool form questionnaire known as the Bristol Stool Chart.
The research found a heavy drinking episode was associated with harder, firm bowel motions.
In particular, those who consumed more alcohol had more Type 1 stools, which are separate hard lumps that look or feel a bit like nuts.
The researchers believed this acute alcohol intake results in small bowel transit delay; the food stayed for longer in the intestines, meaning more water was absorbed from the stool back into the body. This led to drier, harder stools.
Interestingly, the researchers also found there was more of a type of bacteria known as “Actinobacteria” in heavy drinkers than in non-drinkers.
This suggests bacteria may have a role to play in stool consistency.
But binge drinking doesn’t always lead to constipation. Binge drinking in patients with irritable bowel syndrom (IBS), for example, clearly leads to diarrhoea, nausea and abdominal pain.
What can I do about all this?
If you’re suffering from unwanted bowel motion changes after drinking, the most effective way to address this is to limit your alcohol intake.
Some alcoholic beverages may affect your bowel motions more than others. If you notice a pattern of troubling poos after drinking certain drinks, it may be sensible to cut back on those beverages.
If you tend to get diarrhoea after drinking, avoid mixing alcohol with caffeinated drinks. Caffeine is known to stimulate contractions of the colon and so could worsen diarrhoea.
If constipation after drinking is the problem, then staying hydrated is important. Drinking plenty of water before drinking alcohol (and having water in between drinks and after the party is over) can help reduce dehydration and constipation.
You should also eat before drinking alcohol, particularly protein and fibre-rich foods.
Food in the stomach can slow the absorption of alcohol and may help protect against the negative effects of alcohol on the gut lining.
If you’re drinking alcohol, have plenty of water, too. Shutterstock
Is it anything to worry about?
Changes in bowel motions after drinking are usually short term and, for the most part, resolve themselves pretty efficiently.
But if symptoms such as diarrhoea persist beyond a couple of days after stopping alcohol, it may signify other concerning issues such as an underlying gut disorder like inflammatory bowel disease.
Researchers have also linked alcohol consumption to the development of irritable bowel syndrome.
If problems persist or if there are alarming symptoms such as blood in your stool, seek medical advice from a general practitioner.
Vincent Ho ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
In the hit dystopian TV series Severance, employees at biotech corporation Lumon Industries find it easy to separate work and home life. A computer chip is inserted in their brains to act as a “mindwipe”. They leave all thoughts of home behind while at work, and completely forget about their work when at home.
While the show explores the pitfalls of such a split in consciousness, there’s no denying it’s a tantalising prospect to be able to “flick the off switch” and forget about work whenever you’re not actually supposed to be working.
This is known as “psychological detachment”. People who can do it are happier and healthier, and experience less fatigue. But many of us struggle to detach and disconnect mentally from work, particularly when our jobs are demanding and stressful.
It may not be enough simply to be physically away from work, particularly in an era when so many of us work from home. We also have to stop thinking about work when we’re not there – whether it’s fretting over your to-do list while out at dinner, thinking about your unanswered emails while you’re at your daughter’s soccer game, or lying in bed pondering what you’ll say at tomorrow’s board meeting.
The art of detachment
Your choice of activity outside work can be crucial to this process of psychological detachment. To learn more about what strategies are most effective, my research surveyed nurses who were working shifts in hospital emergency departments in 2020, a highly stressful work environment.
My colleagues and I collected data from 166 nurses, using a survey called the Recovery Experience Questionnaire. This included collecting information about the underlying psychological experiences associated with home-time activities, such as feeling relaxed while reading a book or going for a walk.
Importantly, our survey results also showed nurses who were better able to forget about work had less fatigue and better physical and mental health.
Our results identified three key strategies that helped our survey participants to reduce fatigue and mentally recover from work:
exercise
spending time with family and friends
leisure pursuits.
Exercise and spending time with friends are great ways to unwind. Anupam Mahapatra/Unsplash, CC BY
The physical benefits of exercise are well known. But exercising – whether it’s doing yoga, going for a run or playing netball – also brings mental benefits by encouraging you to focus deeply on what you’re doing rather than dwelling on outside thoughts.
Friendship and social connection are also good for our wellbeing. Research suggests people who have plenty of friends and confidants are less likely to die from chronic disease. And one study found people who undertake a difficult task with the help of a friend have fewer abrupt changes in heart rate than those who tackle the task alone.
Deliberately making time to spend with family, friends or pets can help us forget about work at home, and to centre our attention instead on what is important to us besides work.
Many of the nurses in our study reduced the effects of fatigue during home time by pursuing hobbies and interests such as sewing or gardening. But you shouldn’t worry too much about what specific activity you pursue – the main thing is to pick something you find pleasurable and engaging, and which fits comfortably around your existing commitments.
Finally, switching off from work also means not letting your work come home with you. Where possible, complete all your daily tasks so these aren’t on your mind at home. Unplug from work-related technology by not checking work emails or texts.
Of course, technology and working from home have now made separating work and home even harder. But setting healthy routines can help put mental as well as physical boundaries around your work time – even when your workplace is in the next room.
Jane Gifkins ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
The idea that we can comfortably manage all the different facets of life – work, family, other responsibilities – is certainly appealing. But in reality, there is no one-size-fits-all solution to work-life balance – especially for older workers.
Making up a third of the New Zealand workforce, older workers (aged 55 and older) are a growing cohort in the economy.
There is the temptation to treat everyone in this age bracket as the same. But our new research shows this is a mistake. In fact, the support older workers want in order to achieve better work-life balance can differ as they age.
Indeed, the lives of older workers can vary greatly when it comes to employment, family structure, financial resources, time and wellbeing.
As the number of older employees in the economy grows, it’s important to understand what will help keep them satisfied in their work as they move towards and beyond retirement age.
Anxiety, depression and older workers
The goal of our research was to better understand the effects of work-life balance on anxiety and depression caused by job stress among older workers.
We asked two key questions: what effect does work-life balance have on older employees? And are there differences between groups of workers?
We surveyed 512 New Zealand employees in three age groups: 55-59 years, 60-64, and 65-plus. Respondents had been in their current jobs for an average of 12.6 years.
Some 58.2% were in the private sector, 31.6% were in the public/government sector, and 10.2% were in the not-for-profit sector.
In terms of age, 43.8% of respondents fell into the 55–59 age group. Those close to retirement age (60–64) made up 31.3% of respondents, and a further 25% were 65 and older – still working despite being eligible for superannuation.
Work-life balance at different ages
The average levels of work-life balance among the older workers we studied were high, comparing well with similar studies looking at other age groups. Those reporting high levels of work-life balance said they were able to comfortably manage their work, family and other responsibilities.
Job stress (when the demands of work exceed the resources of the employee), job anxiety (when the job is mentally stimulating but not enjoyable), and job depression (when there is little mental stimulation or enjoyment), can all affect wellbeing at work.
The 55–59 year-olds reported higher levels of job stress than older respondents. These younger older workers reported juggling stress that was fuelled by high job demands. Workers in this group were also managing the needs of younger families, often including children in their teenage years.
But respondents reported they experienced less stress in their jobs when their work-life balance was high. They subsequently had lower levels of anxiety and depression.
The younger cohort (55–59 years) reported the strongest benefits of having work-life balance. This effect reduced but remained significant as employees aged.
Respondents who were 65 and older reported a reduction in job stress, and at levels significantly higher than the younger cohort with greater work-life balance.
Our analysis also showed the “retirement” group (those aged 65 and older) had the highest work-life balance, perhaps highlighting the strength of being “retired” (and receiving government income) while also being in paid employment.
At low levels of work-life balance, there was a significant difference in levels of job stress. Those in the younger age group (55–59 years) reported higher levels of job stress than respondents in the older age group.
When we compared this with respondents with high work-life balance, these differences were reversed, with respondents in the younger age group (55–59 years) reporting significantly lower job stress than the older age group.
Overall we found age – and proximity to the traditional retirement age – are important factors in how workers respond to work-life balance. Workers in the 55-59 age group still have a relatively long career ahead. For them, balancing work and life is especially beneficial.
Employers need to think differently
Managers need to understand that older workers are not a uniform group. It is important to develop age-relevant approaches to support the work-life balance of older employees.
Employers also need to consider how to allocate resources to support employee work-life balance across their lifespan.
These measures could include discussing interventions for managing job stress, as well as wellbeing resources that position ageing as positive. For example, using older managers as speakers in organisational wellness initiatives.
Older workers themselves should also seek to understand what drives and diminishes their own work-life balance. It is an important predictor of wellbeing – especially as workers 55 and over could be an “older” worker for decades to come.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’ont déclaré aucune autre affiliation que leur organisme de recherche.
The Boxing Day sales are an essential part of Australia’s festive season.
Every year on December 26 news outlets invariably feature stories about excited shoppers queuing up at the major department stores hoping to score bargains and heavily discounted products. While such reports portray the day’s sales as a time-honoured tradition, they are only a recent ritual.
The origins of Boxing Day date back to the Middle Ages, when English masters gave their servants a day off after the Christmas celebrations. The servants would be given a box containing leftover food and treats to share with their families. In 1871 the day was formally recognised as a public holiday in the United Kingdom. Australian colonies later followed suit.
In the 19th and the early 20th centuries, the Boxing Day holiday was largely a day of rest and entertainment. Community sporting events were often held – a tradition that continues in Australia with the Boxing Day Test in Melbourne and the Sydney to Hobart yacht race.
As Boxing Day was an official public holiday, major retailers like department stores were not permitted to trade. These stores only re-opened for business three to five days after Christmas. Retailers certainly advertised “post Christmas bargains”, but most used this period to prepare for the annual stocktake sales that began shortly after New Year’s Day.
When the day became all about shopping
A gradual shift occurred during the economic boom after the second world war.
As consumer expenditure increased, the competition between retailers intensified. Eager to get ahead of the pack, Myer was advertising its “pre-stocktaking sale” in 1954. As others began their post-Christmas stocktake sales earlier, they became a key part of the retail annual cycle.
By the 1980s retail trading hours were coming under pressure. Since the beginning of the 20th century, retail was confined to 9am-6pm on weekdays and 9am-midday on Saturdays. Changing work patterns meant many Australians were only able to do their shopping in a mad rush on Saturday mornings. Over the 1980s and 1990s, trading hours were progressively extended in each state.
The liberalisation of Victoria’s retail trading hours coincided with a further intensification of competition across the department store sector. Daimaru, a Japanese department store, opened a branch in Melbourne in 1991. In its battle to steal market share from Myer and David Jones, Daimaru pioneered new initiatives, including 24-hour trading in the lead up to Christmas and trading on Boxing Day.
To promote its Boxing Day sale and generate a real buzz, Daimaru advertised a small number of enormously discounted products. These door buster sales worked. Crowds queued in the early hours of the morning to snare one of the bargains. As the doors opened, mayhem ensued as frenzied shoppers literally burst into the store.
The pursuit of a bargain got a little too serious
The appeal of the door buster sale took a hit in 1993 when one eager shopper lost the tips of her fingers in the store’s roller doors. Fearing further carnage, extreme discounts were subsequently dropped, but the crowds hoping to catch a bargain remained. By 2000, Boxing Day sales had become a firmly entrenched tradition.
The door buster sales stopped soon after one keen shopper was injured in the rush. DC Studio/Shutterstock
Although the novelty had faded, Boxing Day sales nevertheless remained an exciting event. Television news crews continued to capture the excitement when the stores opened while newspapers reported on the size of crowds and what this revealed about the state of retail and the economy more generally.
By 2018, a discernible shift was occurring. Fewer people were queuing up and stores were opening later. The major department stores were no longer the dominant retailers they had once been. A broader range of brands and cheaper products could be found elsewhere, notably online, where bargains could be secured without the frustrations of dealing with other frantic shoppers.
The arrival of online shopping
Online shopping changed Australian shopping patterns as bargain hunters could now access overseas sales like Black Friday in the United States. Staged on the day after Thanksgiving, Black Friday is American retail’s busiest day that also kicks off the Christmas shopping season. Sales abound as retailers desperately chase shoppers.
Online has become an integral part of these sales, with Black Friday being extended to Cyber Monday. Australians shopping online have readily joined in.
In 2022 Australians spent an estimated A$7.1 billion over the Black Friday sales period. While this figure is eclipsed by the $23.5 billion predicted for Boxing Day sales period, the reality is the gap is shrinking fast.
This year, it is predicted Australian expenditure on Black Friday will exceed that for Boxing Day.
Will Black Friday overtake Boxing Day?
So, are Boxing Day sales doomed to become another lost tradition? Large discounts and the convenience of shopping online have certainly helped Black Friday’s rapid growth. However, its real advantage is timing. Shoppers not only use these sales for themselves, they can do their Christmas shopping at the same time. Such a combination means Black Friday has quickly become a fixture in Australian retailing.
Of course, Boxing Day sales are not dead. Wherever there are bargains to be had, there will always be shoppers ready to buy. Rather than competing with Black Friday, it seems that the challenge for Australian retailers is to reinvent the Boxing Day sales tradition.
Maybe it’s time to bring back the door buster bargains.
Robert Crawford receives funding from the Australian Research Council’s Discovery Project scheme (DP220100943)
Source: The Conversation (Au and NZ) – By Rebecca Bentley, Professor of Social Epidemiology and Director of the Centre of Research Excellence in Healthy Housing at the Melbourne School of Population and Global Health, The University of Melbourne
Shutterstock
A startling number of Australian rental homes come with an unwanted housemate: mould.
If you discover mould in a rented home, who is responsible and what can you do if the landlord seems unwilling to fix it?
The landlord is responsible if the mould is caused by the structural condition of the property. This can include things like leaking pipes, gutters, roofs or windows.
Tenants are responsible for mould remediation if the way they occupy a home has promoted mould growth. For example, if they have not been using exhaust fans in bathrooms, have been failing to ventilate their home or have been storing wet clothes in a cupboard.
This means establishing the cause of the mould is crucial to working out who’s responsible for repairs.
Establishing the cause of the mould is crucial. Shutterstock
Why are so many rentals mouldy?
Australia has a rental home mould problem chiefly because much of our housing hasn’t been built to suit our climate. Houses tend not to be built with sufficient consideration of:
efficient energy consumption to regulate indoor temperature
the orientation of homes
the use of double glazing and insulation to regulate temperature and humidity.
It is estimated that nearly 17% of privately rented homes and 22% of social housing dwelling require major repairs. This includes structural defects, such as large cracks in walls or leaking gutters, that can generate mould growth.
Tenant representatives have said in the past there is also a problem of weak enforcement of laws concerning the condition of rental homes.
4 ways to cut mould risk
To reduce your mould risk, you need to manage indoor moisture and temperature. Try to:
keep the home well ventilated
open windows and use exhaust fans in the bathroom and kitchen
in humid climates, use air conditioning or a dehumidifier
in cold climate, use a dehumidifier (desiccant dehumidifiers might more appropriate in very cold places)
reduce moisture in the home by wiping up spills and condensation on surfaces
dry washing outside
if buying a dryer, opt for a condensing dryer instead of a conventional dryer (condensing driers put out much less vapour)
report any structural issues (such as leaking pipes or windows that don’t close properly) to the agent or landlord as soon as you notice them.
Don’t dry your washing inside. Shutterstock
Rental minimum standards differ by state or territory
In New South Wales, adequate ventilation is one of the minimum standards properties must meet to be considered fit to live in.
If the rental provider has been notified about mould problems in the house but has failed to act, you might consider getting advice from the Tenants’ Union of NSW.
In Queensland, it depends on when you signed the lease. If you signed after September 1 this year (after new standards were introduced) tenants should notify the landlords of mould as soon as they discover it.
The guidelines in Western Australia say the landlord must ensure the premises is “in a reasonable state of cleanliness and a reasonable state of repair […] and must conduct any repairs within a reasonable period after the need for the repair arises.” And in Western Australia, mould caused by faults in gutters or other fixtures is the responsibility of the rental provider. Further information on what to do if a dispute over the premises can’t be resolved amicably is available on the state government website.
In Tasmania, rental properties must be clean and in good repair when leased out. According to the Tasmanian government website on the issue,
‘Clean’ includes having no […] serious mould/rising damp issues.
If the tenant requests repairs and the landlord doesn’t act, the tenant can lodge a repair order with the Commisioner’s office.
In the Australian Capital Territory, the Tenants’ Union ACT has guidance on what to do if you discover mould in a property you rent.
In the Northern Territory, tenants may wish to seek advice from the Tenants’ Advice Service if there is a mould problem in a property they rent.
What policy change could help?
If the cause of indoor mould is related to the design and construction of the house, rental providers should act. But tenants may not have the information they need to determine and substantiate this claim and can’t do much to get rental providers to act on mould if it’s not clear what’s causing it. Also, renters often worry asking for repairs could lead to a rent increase or eviction.
Solutions include strengthening tenants rights to compel landlords to investigate the cause of mould in a house (given that knowing the cause is essential to assign responsibility for repairs). There should also be more stringent enforcement of current minimum standards relating to mould in rental properties.
Given the scale of problems like mould in Australian homes, policymakers may wish to consider whether a parliamentary inquiry on home environments and health is needed.
This would give Australians a chance to speak about their experiences – something that could help policy makers improve regulation in the rental sector.
Rebecca Bentley receives funding from the National Health and Medical Research Council and the Australian Research Council.
Tim Law is the Technical Lead for Building Sciences at Restoration Industry Consultants (RIC). He has received funding from the National Health and Medical Research Council, the Australian Building Codes Board, the Victorian Building Authority, Consumer Building and Occupation Services (Tasmania) and Commercialisation Australia.
This early sunscreen claimed you could ‘tan with ease’. Trove/NLA
Sunscreens have been available in Australia since the 30s. Chemist Milton Blake made one of the first.
He used a kerosene heater to cook batches of “sunburn vanishing cream”, scented with French perfume.
His backyard business became H.A. Milton (Hamilton) Laboratories, which still makes sunscreens today.
Hamilton’s first cream claimed you could “
Sunbathe in Comfort and TAN with ease”. According to modern standards, it would have had an SPF (or sun protection factor) of 2.
A tan was considered a “modern complexion” and for most of the 20th century, you might put something on your skin to help gain one. That’s when “safe tanning” (without burning) was thought possible.
Sunburn was known to be caused by the UVB component of ultraviolet (UV) light. UVA, however, was thought not to be involved in burning; it was just thought to darken the skin pigment melanin. So, medical authorities advised that by using a sunscreen that filtered out UVB, you could “safely tan” without burning.
But that was wrong.
From the 70s, medical research suggested UVA penetrated damagingly deep into the skin, causing ageing effects such as sunspots and wrinkles. And both UVA and UVB could cause skin cancer.
Sunscreens from the 80s sought to be “broad spectrum” – they filtered both UVB and UVA.
Researchers consequently recommended sunscreens for all skin tones, including for preventing sun damage in people with dark skin.
Up to the 80s, sun preparations ranged from something that claimed to delay burning, to preparations that actively encouraged it to get that desirable tan – think, baby oil or coconut oil. Sun-worshippers even raided the kitchen cabinet, slicking olive oil on their skin.
One manufacturer’s “sun lotion” might effectively filter UVB; another’s merely basted you like a roast chicken.
Since labelling laws before the 80s didn’t require manufacturers to list the ingredients, it was often hard for consumers to tell which was which.
In the 70s, two Queensland researchers, Gordon Groves and Don Robertson, developed tests for sunscreens – sometimes experimenting on students or colleagues. They printed their ranking in the newspaper, which the public could use to choose a product.
An Australian sunscreen manufacturer then asked the federal health department to regulate the industry. The company wanted standard definitions to market their products, backed up by consistent lab testing methods.
In 1986, after years of consultation with manufacturers, researchers and consumers, Australian Standard AS2604 gave a specified a testing method, based on the Queensland researchers’ work. We also had a way of expressing how well sunscreens worked – the sun protection factor or SPF.
Consumers could pick their product based on the sun protection factor or SPF. Shutterstock
This is the ratio of how long it takes a fair-skinned person to burn using the product compared with how long it takes to burn without it. So a cream that protects the skin sufficiently so it takes 40 minutes to burn instead of 20 minutes has an SPF of 2.
Manufacturers liked SPF because businesses that invested in clever chemistry could distinguish themselves in marketing. Consumers liked SPF because it was easy to understand – the higher the number, the better the protection.
Australians, encouraged from 1981 by the Slip! Slop! Slap! nationwide skin cancer campaign, could now “slop” on a sunscreen knowing the degree of protection it offered.
It wasn’t until 1999 that research proved that using sunscreen prevents skin cancer. Again, we have Queensland to thank, specifically the residents of Nambour. They took part in a trial for nearly five years, carried out by a research team led by Adele Green of the Queensland Institute of Medical Research. Using sunscreen daily over that time reduced rates of squamous cell carcinoma (a common form of skin cancer) by about 60%.
Follow-up studies in 2011 and 2013 showed regular sunscreen use almost halved the rate of melanoma and slowed skin ageing. But there was no impact on rates of basal cell carcinoma, another common skin cancer.
By then, researchers had shown sunscreen stopped sunburn, and stopping sunburn would prevent at least some types of skin cancer.
An effective sunscreen uses one or more active ingredients in a cream, lotion or gel. The active ingredient either works:
“chemically” by absorbing UV and converting it to heat. Examples include PABA (para-aminobenzoic acid) and benzyl salicylate, or
“physically” by blocking the UV, such as zinc oxide or titanium dioxide.
Physical blockers at first had limited cosmetic appeal because they were opaque pastes. (Think cricketers with zinc smeared on their noses.)
With microfine particle technology from the 90s, sunscreen manufacturers could then use a combination of chemical absorbers and physical blockers to achieve high degrees of sun protection in a cosmetically acceptable formulation.
Australians have embraced sunscreen, but they still don’t apply enough or reapply often enough.
Although some people are concerned sunscreen will block the skin’s ability to make vitamin D this is unlikely. That’s because even SPF50 sunscreen doesn’t filter out all UVB.
Sunscreens have evolved from something that at best offered mild protection to effective, easy-to-use products that stave off the harmful effects of UV. They’ve evolved from something only people with fair skin used to a product for anyone.
Remember, slopping on sunscreen is just one part of sun protection. Don’t forget to also slip (protective clothing), slap (hat), seek (shade) and slide (sunglasses).
Laura Dawes does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Gregory Moore, Senior Research Associate, School of Ecosystem and Forest Sciences, The University of Melbourne
The airwaves and shopping centres have been filled with Christmas songs and carols. Apparently mommy was seen kissing Santa underneath the mistletoe. Harry Potter’s first kiss was also under a twining white-flowered mistletoe.
Magic, mystery and symbolism surround mistletoes. Their popularity at Christmas comes from their evergreen foliage symbolising life without end.
The festive traditions relate to the English mistletoe, Viscum album, and American mistletoe, Phoradendron leucarpum. These traditions may not apply to our species, but the mystery and magic certainly do.
Australia has nearly 100 species of mistletoes – 75 of them in the plant family Loranthaceae – which are not to be confused with the northern hemisphere species. They occur across the country, except in Tasmania. They are parasitic plants, though for many species their biology is not fully understood.
My interest in mistletoes stems from the many native species that live on common trees such as eucalypts, elms, plane trees, liquidambars, oaks and common fruit trees. Being parasites, mistletoes have often been seen as receivers or even takers, rather than givers, which is hardly in the spirit of the festive season. However, recent research has revealed they are givers too!
Traditional Christmas mistletoes, as shown on this early 20th-century card, are the white-berried American and English species. Royce Bair/Flickr, CC BY-NC-ND
Indigenous communities were well aware of the sweet sticky fruits and the medicinal benefits certain mistletoe species provided. They also used mistletoes as a general indicator of the condition of Country and as part of fire management. Some may have used the foliage in their cleansing and welcome ceremonies too.
You may be thinking it’s a mystery why you haven’t noticed these plants more often. That’s explained by a bit of mistletoe magic.
Many of our species have a brilliant camouflage. Their leaves mimic those of the host tree (a phenomenon called crypsis). So mistletoes such as Amyema miguelli and A. pendula have leaves that resemble those of eucalypts, but they become conspicuous when they flower.
Mistletoes are hemi-parasites, which means they have green leaves and photosynthesise like other plants, but take water and nutrients from their hosts. They do this by tapping into the transport system inside the host plant and diverting some of the water and nutrients it contains.
Mistletoe leaves can look a lot like those of their host, such as this box mistletoe (Amyema miquelii) on a yellow box (Eucalyptus melliodora) tree. Arthur Chapman/Flickr, CC BY-NC-SA
Mistletoes shed more leaves more often than other plants of comparable size. These leaves contain valuable elements and compounds. This shedding creates a litter layer and compost that enriches the soil and increases the biodiversity not only in the soil but in the environment around them.
It isn’t just other plants that benefit from these gifts. The numbers of different insects, spiders and fungi present in the leaf litter goes up significantly where mistletoes are present. So too does the diversity of birds and other animals.
Many native mistletoes have spectacular and colourful flowers. These are an important source of food for many insect and bird species.
This means mistletoes are important for the biodiversity of the ecosystems that contain them.
There is more mistletoe magic! Mistletoes often have a dense foliage, which creates a cooler microclimate in their vicinity. Mistletoes also continue to transpire water when other plants have ceased due to dry conditions, which further cools the air.
There is evidence that birds and mammals nest in the denser cooler mistletoe foliage in preference to other more abundant plants growing around them. Animals also take refuge within and under mistletoes when it’s very hot. This benefit for native wildlife may be all the greater as climate changes.
We tend to notice mistletoes when flowering and bird feeding peak, or when their evergreen foliage stands out against the bare branches of deciduous host trees. We can then be surprised at how many mistletoes are growing in the canopy of a tree in our garden.
In some parts of Australia, the number of mistletoes can increase over time such that large numbers on a single host can sap the tree’s vigour. Branches beyond the point of mistletoe attachment die back, particularly on older trees and in drier seasons. When there are more than 20 mistletoes per tree, both its growth rate and flowering are reduced.
In hot dry conditions, high mistletoe numbers can lead to the deaths of older, stressed trees. Changes to fire regimes and the clearing of native vegetation are likely causes of increased mistletoe infestation.
For your garden trees, some appropriate mistletoe control may benefit not only your trees but the mistletoes too. Mistletoe control requires a sophisticated approach because of their importance for local ecosystems.
A large tree with a full canopy in good condition can cope with about four to six mistletoes. Survey mature trees to ascertain mistletoe numbers and take steps to control some, but not all, of the mistletoes if infestations are excessive.
To remove mistletoe, cut the connection to the host tree as close as possible to the branch or trunk without damaging the host. In some cases there may be more than one connection and so several cuts may be required. Sometimes nature will take control as mistletoes can die from excessive water loss during heatwaves.
Australia has two native mistletoes associated with Christmas: the cherry ballart (Exocarpos cupressiformis) and the Western Australian Christmas tree (Nuytsia floribunda). John Tann/Flickr, Grame Churchard/Wikimedia Commons, CC BY
A home-grown Christmas tradition
Not all mistletoes grow in tree canopies. Some are root parasites. They include the cherry ballart, Exocarpos cuppressiformis, and the spectacular Western Australian Christmas tree, Nuytsia floribunda.
The latter is renowned for its abundant brilliant yellow-orange flowers over the Christmas period. Early settlers used the cherry ballart with its conifer-like foliage as a Christmas tree with or without its red “cherries” as decoration. The “cherries” are not true fruits, but swollen fruit stalks – another bit of mistletoe magic and mystery.
Gregory Moore does not work for, consult, own shares in or receive funding from any company or organization that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Sleep, along with diet and physical activity, is one of the three pillars of good health. Good sleep makes it easier to grow, learn, perform, be happy, stay in our best weight range and generally be in the best mental and physical health. This is true for all humans but is particularly important with children.
Regular sleep patterns are important for good sleep. But children and their families often stay with relatives or in holiday accommodation around this time of year. Parents may anxiously wonder: will changing sleeping arrangements during school holidays sabotage good habits formed and maintained during the school term?
For over 20 years, I have researched and treated children sleep problems. The research suggests changing sleep patterns over the summer break does not have to be a problem. And there’s a lot you can do to manage sleep issues during and after the holidays.
Changing sleep patterns over the summer break does not have to be a problem. Shutterstock
In Australia, as in many western industrialised countries, parents often (but not always) expect their children to sleep alone in their own room and in their own bed.
Up to 40% of families use behavioural sleep strategies to teach their child sleep alone. While such strategies are generally successful in achieving this, it can be hard work for all the family.
Many parents worry that having children share a room or even a bed with their parents over the holidays will become the habit during term time, too.
However, the science says once children have learned a skill, such as sleeping alone, they have a “neural understanding” of that skill. That means their brain has registered, recorded and filed the “memory” of sleeping alone and this is stored for quite a long time.
Short relapses or interruptions to using that skill will not eradicate it in the brief time of a holiday. The child will still know how to sleep alone.
Children may may realise sleeping with parents or siblings is actually pretty great (for them). It may be less fun, however, for the parents (who may not necessarily want to share a bed with a wriggly child, or feel frustrated by seeing siblings who don’t normally share a room, muck around when they should be asleep).
Like many aspects of parenting, it helps for parents to remind their children of the rules at home and guide them back to their regular sleep pattern.
Helping children to understand the co-sleeping or room sharing arrangement may be temporary is helpful. Children can and do learn sleeping arrangements can be different in different places, but the rules stay the same at home.
Sometimes, being on holidays means sharing a room with your sibling or cousins for the first time. Shutterstock
What if my child won’t sleep at the holiday accommodation?
This is a problem not just because it keeps parents and others from a good night’s sleep. It also deprives the child of sleep.
For some children, particularly sensitive or anxious children, changing sleep routines and particularly sleep environments can really throw them off. These children may find any change very difficult.
When these children are faced with an unknown sleeping environment, they may keenly feel the separation from their parents (who make them feel safe). It can be very difficult and sometimes impossible for them to adjust quickly.
The result may be a child taking a longer time to get to sleep, or long and unsettled overnight wakings. Parents may need to mentally prepare and adjust their expectations.
Like many adults, some children struggle to sleep in an unfamiliar environment. Shutterstock
It may help to prepare the child for the changes. Find out information about sleeping arrangements, before you go to your holiday accommodation. Talk to the child about the sleep set up, who will be there, look at pictures and share the excitement of a new place with the child.
Discuss being scared and anxious with the child and learn some strategies together to help them be brave and calm such as “You will have your favourite bunny with you. And we will just be in the next room”? Or, “We can take our night light from home?” Practise these before leaving on the holiday.
Encouraging and helping your child to be brave rather than expecting them to be brave alone is more likely to result in a smoother transition from home to holiday and back again. Don’t shame them for feeling scared, but try to gently and empathetically help them learn some strategies to cope. Facing a difficult challenge such as changing sleep environments will also teach them resilience.
So parents don’t need to fear any negative repercussions from changing sleeping environments during the summer holidays. Bring on summer and enjoy.
Sarah Blunden does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
In 1998, Victorian premier Jeff Kennett visited a town in regional Victoria and said he had discovered, in his opinion, the best vanilla slice in Australia at the local bakery. He was so inspired by his slice experience that he established a new competition to determine, conclusively, Australia’s best vanilla slice. The inaugural “Great Australian Vanilla Slice Triumph” was held in Ouyen, Victoria on October 23 that year.
Kennett’s press release promoting the event declared this “important Australian culinary delicacy has tantalised Australians since white settlement” and “the pursuit of the best vanilla slice and the best vanilla slice baker in Australia should be of great national interest”.
The competition became an annual event, hosted at Ouyen until 2001, when the honour was passed to nearby Merbein and has continued.
After some COVID-related cancellations, the contest was on again in 2023. Judges advise entrants on the Triumph website that they are looking for “a custard with a creamy smooth texture and a balance of vanilla taste with a crisp crunchy pastry topped with a smooth and shiny glaze fondant”. North End Bakehouse in Shepparton, Victoria took first place this year, fulfilling baker Matt Aylett’s career-long quest for top honours.
Proclaimed as a national icon, the vanilla slice is a familiar sight in Australian bakeries – but where did this pastry come from?
Slices from around the world
Across Europe and the United States there are many versions of the vanilla slice, with the earliest mention found in a 1651 French cookbook as a gateau with frangipane.
The French version is called a mille-feuille, translated as “one thousand leaves” of pastry created by repeatedly folding a thin sheet of butter wrapped inside a dough covering. In the oven, the butter melts and its water content creates steam, separating the dough to make countless crunchy layers.
A mille-feuille is a much more delicate affair. Shutterstock
Unlike the Aussie slice with its thick layer of custard, the mille-feuille has three sheets of puff pastry and only a centimetre of crème pâtissière in between.
In America, the same three-layer design is called a Napoleon, a corruption of Napoletana, referencing the origin of another version from Naples.
In Poland, there is the kremowka; in the Netherlands, the tompouce; in Serbia, the krempita; in Croatia the kremšnite; and then the caramel-covered version, the Hungarian Szegedinertorte.
In Poland, you can have a kremowka. Shutterstock
With similar versions across the globe, it is impossible to trace the genealogy of the Australian treat, but the combination of crunch and cream clearly has universal appeal.
Replacing the plain English name (vanilla slice, custard block) with an irreverent and outrageous moniker (“snot block” or “phlegm sandwich”) is standard practice in Australia, where informality and a lack of pretence are hallmarks of the vernacular.
The Macquarie Dictionary blog suggests that “snot block” is a regionalism that originated in central Victoria, with less frequently cited variants in other states, including “snot brick”, “phlegm cake” and “pus pie”.
Has the original delicate nature of the pastry followed the slide into slang from the French mille-feuille to snot block? The slice has grown in size over time, now with so much filling it can be difficult to eat gracefully. Extra skill is also required of the baker, tasked with making a custard-filled tower with the structural stability to stand on its own.
The baker’s slice?
Consulting the archives of Australian Women’s Weekly provided tips and tricks offered to help home bakers “make your custard set”.
For a dainty portion, with an extra layer of puff pastry, this is not a challenge.
Traditional pastry cream is not expected to be sliced like a jelly – it is a filling for cream puffs and eclairs.
The taller the slice, however, the more thickening power is required, usually in the form of cornstarch, gelatine or pudding mix. This is a delicate balancing act, however, as too much thickener produces a filling with the consistency of a bouncy ball, and too little will result in an uncontrollable blob.
Cooking the custard just enough to maximise the thickening power of the cornstarch but not scramble the eggs is also a tricky business, requiring either a keen eye or a thermometer and constant supervision.
This may account for the staying power of the vanilla slice in the bakery, especially in its new high-rise evolution. Only the most daring of home cooks would tackle such a temperamental recipe, only to have guests say “Oh, you made snot block!”
Imported from Europe, the vanilla slice has been fully assimilated into Australian food culture, an identifiable icon. A sure measure of its acceptance as a genuine element of Aussie culture is its unpretentious alias – snot block. You know you really belong when you finally get a nickname.
Garritt C Van Dyk does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Source: The Conversation (Au and NZ) – By Michael David Barbezat, Research Fellow, Institute for Religion and Critical Inquiry, Australian Catholic University
The Beast Acheron, 1475
Simon Marmion (Flemish, active 1450–1489)Getty Museum
There is an obscure medieval legend that says once upon a time in Bethlehem, a child was born whose holiness was so great it required the slaughter of all the “sodomites” in the world.
Sodomites, the legend says, are so impure God did not want to share His humanity with them. So, He killed them all before He became human.
Clearly, there was no divine annihilation of sodomites on the first Christmas. Nonetheless, this curious example of medieval “fake news” is important because of what it represents.
The story combines ridiculous assertions and pious hatred in a manner familiar to many queer people today. What a medieval theologian meant by “sodomite” is not the same thing as what we mean today by “homosexual”. Yet, religious condemnations of “sodomy” are all too often applied to contemporary LGBTQ+ people.
A false legend
The medieval authorities who cited the legend believed it was fact. Their faith in the story rested on its supposed origins in the writing of Saints Jerome and Augustine, as explained by James of Voragine (c. 1230–1298) in his famous collection of saints’ lives called the Golden Legend.
James of Voragine wrote that Jerome and Augustine spoke of how “even the sodomites gave witness by being exterminated wherever they were” on Christ’s birth, because God hesitated to become incarnate while this vice existed in human nature.
The sudden death of all the world’s sodomites, of course, did not happen on the first Christmas. What is more, Jerome and Augustine never actually claimed it did. People who have looked in their works for the legend’s origins have found nothing.
The legend probably began with Stephen Langton, later the Archbishop of Canterbury. Jules & Jenny/flickr, CC BY
Every part of the legend is false.
As far as I can tell, the story began in the classroom of Stephen Langton (c. 1150–1228) in Paris.
Langton was an intellectual who became the Archbishop of Canterbury and famously played a role in the events leading up to England’s Magna Carta.
Before all that, Langton in a lecture repeated a rumour he had heard about another great Parisian teacher, Peter the Chanter. He had heard Peter the Chanter had said he had read Jerome and Augustine who had said the world’s sodomites had died on the first Christmas.
Langton admitted he could not find where Augustine had made this claim.
Langton’s many students – who became some of the most influential and powerful men in history – repeated the story anyway. It conveyed what they wanted to be true. We can find it in saints’ lives, sermons, devotional works, compendiums of theology, and inquisitorial handbooks from the 13th to the 16th centuries and beyond.
Saints and theologians used the legend to solve apparent problems.
The great Italian preacher Bernardino of Siena (1380–1444) turned to the Christmas slaughter of the sodomites to explain why it was Jesus never mentioned sodomy, instead focusing on other vices like hypocrisy.
Saint Bernardino of Siena Preaching, Giovanni di ser Giovanni Guidi, called Lo Scheggia, mid-15th century. Birmingham Museum of Art
Bernardino – one of the most influential preachers in 15th-century Italy – especially detested sodomy, as well as witches and Jews. In a sermon preached at Florence in 1425, Bernardino explained Jesus did not address sodomy because there were no sodomites.
He “quoted” Jerome’s claim that all the sodomites in the entire universe died at Jesus’ birth, and said during Jesus’ ministry the practice had not re-emerged because of the fresh terror of God’s massacre. The saint urged the authorities of his day to follow God’s example and suggested the local sodomites be thrown into fires in the street.
Medieval thinkers’ ideas regarding sexual morality are still with us.
They especially endure in the connection between “sodomy” and modern homosexuality in some religious traditions. In official Catholic speech during the last century, as the theologian Mark Jordan has summarised:
‘Homosexuality’ took the place of ‘sodomy’ in the way a substitute teacher takes over a class.
Some modern far-right commentators have rediscovered the legend, celebrating its traditional values and saintly authority.
Today, we can see the Christmas slaughter of the sodomites as both baseless fantasy as well as indicative of traditional religious values regarding sexuality. Such values still connect “deviant” sex to deserving death. One of the early names for HIV was “WOGS”, or wrath of God syndrome. Televangelist Pat Robertson famously suggested AIDS was “God’s way of weeding his garden”.
We can also see the continuing power of the same violent impulse found in the Christmas legend in persecutions of queer people across the world, especially of trans people.
This legend, at its core, argued that God hated certain types of sexual behaviour more than He loved the people He had made.
Today, religious extremists channel the arguments, conclusions and spirit of centuries of murderous condemnations of sexual practices and identities.
The obscure medieval legend of the Christmas slaughter of the world’s sodomites is one example of how such persecutory traditions are rooted in prejudices presented as facts. It shows us the saints were frequently wrong, and their errors are now woven into what seem to be our traditions.
Michael David Barbezat does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
As many as 90% or more of pregnant people experience some degree of nausea or vomiting, often colloquially referred to as “morning sickness”.
For some, it is relatively mild, coming and going during the first trimester without much fuss. For others, it can be severe, life-changing and traumatic.
But the term “morning sickness” is a misnomer. Findings clearly show nausea and vomiting can occur throughout the day.
A recent and novel study had pregnant women complete a symptom diary for each hour of the day across the first seven weeks of pregnancy. It found while peak symptoms occur in the morning, almost as many women experienced symptoms in the late afternoon or night as did in the morning.
Frequent symptoms of nausea and vomiting can become a significant problem, impacting an individual’s health, wellbeing and ability to perform basic tasks.
Given nausea and vomiting in pregnancy is frequently misunderstood and its effects often underestimated, its incorrect naming contributes to the stigma and lack of effective treatments faced by many women.
The severe impacts of nausea and vomiting in pregnancy
The most severe form of nausea and vomiting in pregnancy is called hyperemesis gravidarum and is reported to affect up to 3.6% of pregnant women. Women with hyperemesis gravidarum have severe and persistent symptoms that can make it difficult for them to eat and drink enough. It can lead to weight loss, dehydration, and nutritional deficiencies.
It can also have a big impact on a person’s emotional, mental and physical health. Some people might be too sick to work, look after themselves or others, or complete normal daily activities. The economic and psychosocial effects of this can be profound.
In addition, recent studies report high rates of pregnancy termination, as well as suicidal thoughts, among hyperemesis gravidarum sufferers. This is on top of the range of adverse pregnancy outcomes (such as low birth weight) associated with the condition.
Even when not considered severe enough to constitute hyperemesis gravidarum, nausea and vomiting in pregnancy can still have profound impacts, greatly impacting women’s health, mental wellbeing, work, relationships, quality of life and experience of pregnancy.
While the significant burden of nausea and vomiting highlights the importance of early and effective treatment, the reality faced by many women paints a different picture. A recent Australian survey found one in four respondents reported being denied medications for treating nausea or hyperemesis.
In part, this could reflect the ongoing hesitancy towards using medications during pregnancy since the thalidomide tragedy in the 1960s. But it also reflects the enduring stigma those experiencing nausea and vomiting in pregnancy face when trying to receive care.
As recently as the early 1900s, the root cause of nausea and vomiting in pregnancy was thought to be psychological. Journal articles referred to “hysteria” as a principal cause of nausea and vomiting, and of individuals manifesting symptoms as a result of being unhappy with their pregnancy or marriage, or seeking attention.
These erroneous beliefs have led to various dismissive and damaging practices resulting in women feeling isolated and unsupported. A 2004 French study reported treating women admitted to hospital for hyperemesis gravidarum by subjecting them to isolation from friends or family to see if they would reveal their “secret desire” for an abortion.
Biologists have argued nausea and vomiting in pregnancy serves a beneficial function to protect mothers and their unborn children from potentially harmful exposures. In part, this is based on evidence those experiencing nausea and vomiting in pregnancy are less likely to have a miscarriage.
While it seems to be accurate that nausea and vomiting in pregnancy has benefits, this argument presents it as a “rite of passage” and something individuals should welcome, while trivialising its associated burden.
How should nausea and vomiting in pregnancy be defined?
While nausea and vomiting in pregnancy is common, when prolonged it can quickly become a debilitating medical condition. It’s important individuals experiencing nausea and vomiting in pregnancy are listened to and get the treatment they need, rather than being dismissed.
Guidelines often recommend using screening tools which classify individuals as having mild, moderate or severe nausea and vomiting based on responses to three questions about how they have been feeling over the past 24 hours.
While tools like this can be useful to guide or monitor treatment, they can risk causing further harm if used to restrict access to care based on perceived symptom severity. It’s crucial that treatment decisions not be based solely on a number, but rather on a comprehensive evaluation of an individual’s emotional, mental and physical health.
Pregnancy sickness should be seen as an illness to be managed, not a rite of passage. SeventyFour/Shutterstock
Time to retire the term ‘morning sickness’
A term that incorrectly describes the nature and spectrum of an illness can be expected to further perpetuate stigmas faced by those seeking clinical care. Given it’s well recognised the term is felt by many to downplay the condition, we must ask ourselves why we continue to use the term “morning sickness”.
This description is inaccurate, simplistic, and therefore unhelpful. Referring to the illness by what it is, nausea and vomiting in pregnancy or “NVP”, could reduce stigma and lead to better outcomes for sufferers.
Perhaps more important is recognition that not all nausea and vomiting in pregnancy is experienced equally, and treating it as such risks trivialising the experience of each individual.
Luke Grzeskowiak receives funding from the Channel 7 Children’s Research Foundation, The Hospital Research Foundation and National Health and Medical Research Council.
Hannah Jackson receives an Australian Government Research Training Program Stipend from the University of Technology Sydney.
There’s no shortage of apps and technology that claim to shift the brain into a “theta” state – said to help with relaxation, inward focus and sleep.
But what exactly does it mean to change one’s “mental state”? And is that even possible? For now, the evidence remains murky. But our understanding of the brain is growing exponentially as our methods of investigation improve.
Brain-measuring tech is evolving
Currently, no single approach to imaging or measuring brain activity gives us the whole picture. What we “see” in the brain depends on which tool we use to “look”. There are myriad ways to do this, but each one comes with trade-offs.
We learnt a lot about brain activity in the 1980s thanks to the advent of magnetic resonance imaging (MRI).
Eventually we invented “functional MRI”, which allows us to link brain activity with certain functions or behaviours in real time by measuring the brain’s use of oxygenated blood during a task.
We can also measure electrical activity using EEG (electroencephalography). This can accurately measure the timing of brain waves as they occur, but isn’t very accurate at identifying which specific areas of the brain they occur in.
Alternatively, we can measure the brain’s response to magnetic stimulation. This is very accurate in terms of area and timing, but only as long as it’s close to the surface.
What are brain states?
All of our simple and complex behaviours, as well as our cognition (thoughts) have a foundation in brain activity, or “neural activity”. Neurons – the brain’s nerve cells – communicate by a sequence of electrical impulses and chemical signals called “neurotransmitters”.
Neurons are very greedy for fuel from the blood and require a lot of support from companion cells. Hence, a lot of measurement of the site, amount and timing of brain activity is done via measuring electrical activity, neurotransmitter levels or blood flow.
We can consider this activity at three levels. The first is a single-cell level, wherein individual neurons communicate. But measurement at this level is difficult (laboratory-based) and provides a limited picture.
As such, we rely more on measurements done on a network level, where a series of neurons or networks are activated. Or, we measure whole-of-brain activity patterns which can incorporate one or more so-called “brain states”.
According to a recent definition, brain states are “recurring activity patterns distributed across the brain that emerge from physiological or cognitive processes”. These states are functionally relevant, which means they are related to behaviour.
Brain states involve the synchronisation of different brain regions, something that’s been most readily observed in animal models, usually rodents. Only now are we starting to see some evidence in human studies.
Various kinds of states
The most commonly-studied brain states in both rodents and humans are states of “arousal” and “resting”. You can picture these as various levels of alertness.
Studies show environmental factors and activity influence our brain states. Activities or environments with high cognitive demands drive “attentional” brain states (so-called task-induced brain states) with increased connectivity. Examples of task-induced brain states include complex behaviours such as reward anticipation, mood, hunger and so on.
In contrast, a brain state such as “mind-wandering” seems to be divorced from one’s environment and tasks. Dropping into daydreaming is, by definition, without connection to the real world.
We can’t currently disentangle multiple “states” that exist in the brain at any given time and place. As mentioned earlier, this is because of the trade-offs that come with recording spatial (brain region) versus temporal (timing) brain activity.
Brain state work can be couched in terms such as alpha, delta and so forth. However, this is actually referring to brain waves which specifically come from measuring brain activity using EEG.
EEG picks up on changing electrical activity in the brain, which can be sorted into different frequencies (based on wavelength). Classically, these frequencies have had specific associations:
gamma is linked with states or tasks that require more focused concentration
beta is linked with higher anxiety and more active states, with attention often directed externally
alpha is linked with being very relaxed, and passive attention (such as listening quietly but not engaging)
theta is linked with deep relaxation and inward focus
and delta is linked with deep sleep.
Brain wave patterns are used a lot to monitor sleep stages. When we fall asleep we go from drowsy, light attention that’s easily roused (alpha), to being relaxed and no longer alert (theta), to being deeply asleep (delta).
Brainwaves are grouped into five different wavelength categories. Shutterstock
Can we control our brain states?
The question on many people’s minds is: can we judiciously and intentionally influence our brain states?
For now, it’s likely too simplistic to suggest we can do this, as the actual mechanisms that influence brain states remain hard to detangle. Nonetheless, researchers are investigating everything from the use of drugs, to environmental cues, to practising mindfulness, meditation and sensory manipulation.
Controversially, brain wave patterns are used in something called “neurofeedback” therapy. In these treatments, people are given feedback (such as visual or auditory) based on their brain wave activity and are then tasked with trying to maintain or change it. To stay in a required state they may be encouraged to control their thoughts, relax, or breathe in certain ways.
The applications of this work are predominantly around mental health, including for individuals who have experienced trauma, or who have difficulty self-regulating – which may manifest as poor attention or emotional turbulence.
However, although these techniques have intuitive appeal, they don’t account for the issue of multiple brain states being present at any given time. Overall, clinical studies have been largely inconclusive, and proponents of neurofeedback therapy remain frustrated by a lack of orthodox support.
Other forms of neurofeedback are delivered by MRI-generated data. Participants engaging in mental tasks are given signals based on their neural activity, which they use to try and “up-regulate” (activate) regions of the brain involved in positive emotions. This could, for instance, be useful for helping people with depression.
Another potential method claimed to purportedly change brain states involves different sensory inputs. Binaural beats are perhaps the most popular example, wherein two different wavelengths of sound are played in each ear. But the evidence for such techniques is similarly mixed.
Treatments such as neurofeedback therapy are often very costly, and their success likely relies as much on the therapeutic relationship than the actual therapy.
On the bright side, there’s no evidence these treatment do any harm – other than potentially delaying treatments which have been proven to be beneficial.
Susan Hillier receives funding from Medical Research Future Fund/NHMRC.
Antarctica is often imagined as the last untouched wilderness. Unfortunately, avian influenza (“bird flu”) is encroaching on the icy continent. The virus has already reached the sub-Antarctic islands between the Antarctic Peninsula and South America. It’s only a matter of time before it reaches the Antarctic continent.
So far avian influenza has been detected in several seabird species on South Georgia Island and the Falkland (Malvinas) Islands. These birds are known to travel to Antarctica. Researchers also suspect avian influenza caused mass deaths of southern elephant seals.
The arrival of avian influenza in Antarctica could have potentially catastrophic consequences for the wildlife, decimating large populations.
Antarctic avian influenza outbreaks may also disrupt tourism and research activities during the busy summer season. So what can we do during this challenging time?
We are in the midst of a “panzootic” – a large-scale pandemic of avian influenza, which is occurring across the world and has affected more than 200 species of wild birds.
While this strain of avian influenza (H5N1) is an old foe, the genetics and epidemiology of the virus have shifted. Once mostly found in poultry, it is now infecting large numbers of wild birds. Migrating birds have spread the virus with substantial outbreaks now occurring in Europe, Asia, Africa, North America and South America.
Avian influenza has devastated seabird populations around the world, including a 70% reduction of northern gannets on Bass Rock in the United Kingdom. Many birds are diseased, with signs including loss of coordination, watery eyes, head twisting, breathing distress or lethargy.
The first detection of avian influenza near Antarctica occurred in early October on Bird Island, South Georgia, in brown skuas (seabirds similar to large gulls).
A case on the Falkland (Malvinas) Islands was confirmed a few weeks later in another seabird species, the southern fulmar.
The Antarctic Peninsula, with its ice-free areas, is an important breeding ground for many key Antarctic species.
Critically, those species – and others, including the iconic Emperor penguin – live in dense colonies and are not found elsewhere in the world, making them particularly vulnerable to disease outbreaks.
Outbreaks on the Antarctic Peninsula will also be extremely disruptive to the tourism industry. More than 104,000 people visited as tourists in the 2022–23 season. People visit to see wildlife, make a continental landing, and enjoy the scenery.
Once avian influenza is confirmed at a particular location, sites will be closed to tourists. This will lead to a different experience for visitors, with land-based wildlife encounters pivoting to cruise-based activities.
What are we doing?
The Antarctic Wildlife Health Network of the Scientific Committee on Antarctic Research has developed recommendations for the research and tourism communities.
These recommendations include information around biosecurity, testing and reporting of cases. The network’s database collates information on suspected and confirmed cases of the H5N1 avian influenza strain in the Antarctic region. This is central to rapid data sharing.
During the 2022–23 season, a small number of researchers tested suspected cases and conducted surveys, which excluded the presence of avian influenza.
This year, through the generosity of industry partners, we will dramatically expand this effort. The network will conduct surveys across the Antarctic and sub-Antarctic to monitor the presence and impact of the virus on wildlife.
Safety and biosecurity measures have been boosted across the scientific community and tourism industry to reduce the risk of people spreading the virus. This should ensure essential scientific research and tourism activities can continue safely.
New measures now in place include:
disinfection of boots and outer clothing
wearing of N95 masks, protective glasses and gloves when working with wildlife
restrictions on access to infected sites.
Tourism can play an important role in detecting and monitoring the spread of the virus, alerting authorities to new cases in locations not visited by scientists.
The International Association of Antarctica Tour Operators is on high alert. Extra training for field staff will help them identify wildlife illness quickly.
Antarctica is connected
Many threats to Antarctica – including climate change, pollution, and pathogens – originate elsewhere. Climate change is expected to increase the spread of infectious diseases in wildlife and Antarctica is not immune.
Disease surveillance and information sharing between all those active in the far south are vital to help minimise the impacts of avian influenza and future disease threats.
The avian influenza example highlights the connectivity of our world, and why we need to care for the planet at home in order to protect the far south.
Hanne E F Nielsen receives funding from the Australian Research Council, Linkage partner organisation Intrepid Travel, the Dutch Research Council, and the Australian Antarctic Division. Hurtigruten Australia provides in-kind support for fieldwork.
Michelle Wille has an honorary appointment with the WHO Collaborating Centre for Reference and Research on Influenza.
Meagan Dewar ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son organisme de recherche.
Source: Council on Hemispheric Affairs – Analysis-Reportage
Roger D. Harris
Alex Saab was freed from US captivity in what Venezuelan Prof. Maria Victor Paez described as “a triumph of Venezuelan diplomacy.” The diplomat had been imprisonedfor trying to bring humanitarian supplies to Venezuela in legal international trade but in circumvention of Washington’s illegal economic coercive measures, also known as sanctions.
Negotiated prisoner exchange
In a prisoner exchange, Venezuela released ten US citizens and some other nationals to free Alex Saab after his over three years of imprisonment.
Saab’s plane landed in Venezuela on December 20. He was tearfully greeted by his family, friends, and Venezuela’s primera combatiente Cilia Flores, wife of the president. Shortly after, President Nicolás Maduro made a triumphal public address with Alex Saab at his side at the presidential palace.
Unlike Maduro, US President Biden made no such public address with his releasees beside him. Had he done so, he would have had to stand with “Fat Leonard” Francis, who had escaped US captivity after being convicted in a major US Navy corruption caseimplicating some sixty admirals. The US badly wanted him back in their custody. He knew too much about officials in high places.
The White House has so far declined to reveal the full list of those released. John Kirby, US Security Council spokesperson, tweeted, “Sometimes tough decisions have to be made to rescue Americans overseas.” Among the others released were mercenaries Luke Deman and Airan Berry, who were captured after the “Bay of Piglets” attempt to assassinate the Venezuelan president.
The US government would have liked nothing more than to have locked Alex Saab up and thrown away the key. And for a while, it looked like that was going to happen. Saab’s crack legal team had tried unsuccessfully to free him on the grounds that he was a diplomatwho, under the Vienna Convention for Diplomatic Relations, is supposed to enjoy absolute immunity from arrest. Although the US is a signatory to the convention, Uncle Sam saw no reason to abide by international law.
The US Department of Justice lawyers argued, in effect, that because the US does not recognize the legitimacy of the democratically elected government in Venezuela, it certainly does not have to accept its diplomats. Although appeals were made, the US government simply delayed the case.
In short, the likelihood of achieving justice from the US justice system was slim. The last hope for freeing Alex Saab was a prisoner exchange. And that turned out to be the route to freedom.
How the campaign succeeded
The saga of Alex Saab and his ultimate emancipation is similar to the campaign to free the Cuban 5. The five had infiltrated terrorist groups in the Miami area, which were planning attacks on Cuba. When the Cuban authorities notified the FBI in 1998 of these illegal actions being planned on US soil, the US government instead arrested the five Cuban heroes, as they became to be known in their homeland.
Cuban President Fidel Castro vowed that the five would be freed, and they were. Two of the five eventually completed their prison sentences. Then in 2014, the remaining three were released in a prisoner exchange after a successful international campaign.
Like the campaign to free the Cuban 5, the FreeAlexSaab campaign rested on four legs: the remarkable resoluteness of Alex Saab himself, the mobilization of the entire Venezuelan nation on his behalf, an international movement, and the support and involvement of his family.
Alex Saab’s resoluteness was exemplary. Unlike many prisoners, Saab had a get-out-of-jail-free card that he could have played if he had chosen to do so. He did not.
As US officials admitted, Saab was a high value asset because he had information that the US security state wanted regarding contacts and means to circumvent the illegal coercive economic measures. All he had to do was sing and renounce Venezuelan President Maduro and the Bolivarian Revolution. But he did not, even under extreme pressure. Not simply pressure, but he was tortured while imprisoned in Cabe Verde.
In his emotional welcoming speech to Alex Saab, President Maduro remarked on Saab’s Palestinian heritage, noting that came with a capacity to resist. Venezuela has been among the Latin American nations most critical of the Israeli assault on Palestine.
The second pillar to the successful campaign was the mobilization of the Venezuelan nation behind freeing their national hero. This mobilization extended from the grassroots to the head of state.
Maduro noted that even while Saab was languishing in jail, the diplomat’s efforts had not been in vain. Although Saab was behind bars for 1280 days, the Venezuelan people were benefiting from the vaccines, food, and fuel that Saab had arranged to be delivered, circumventing the US blockade. Sharing the podium with them at the welcoming speech was a high-ranking Venezuelan general who, hearing this, cried.
Efforts of friends and family
The third element in the successful effort was launching an international campaign to #FreeAlexSaab. All over the world, friends of Venezuela’s sovereignty united to hold actions demanding his freedom.
Out of Vancouver, Canada, Hands Off Venezuela! conducted monthly online virtual picket lines featuring guest speakers on the Saab case. British rock star Roger Waters spoke out for Alex Saab’s freedom, as did distinguished Nigerian lawyer Femi Falana, United Nations special rapporteurs Alfred-Maurice de Zayas based in Switzerland and Alena Douhan based in Belarus, international law expert Dan Kovalik at the University of Pittsburgh, and Puerto Rican national hero and former political prisoner Oscar Lopez Rivera. Also weighing in on the injustice to Alex Saab were the American Association of Jurists, the National Lawyers Guild, United Nations Human Rights Committee, and the African Bar Association, along with the Economic Community of West African States’ (ECOWAS) Court of Justice.
Head of the North American FreeAlexSaab Campaign, Venezuelan-American William Camacaro commented that this was an important victory for President Maduro and by extension the larger Bolivarian Revolution. An already fractious opposition in Venezuela, he observed, has gotten even more divided while the Chavista movement is more unified going into the 2024 presidential election year.
Parallel campaigns for a prisoner exchange were waged on behalf of US citizens imprisoned in Venezuela. Prominent among those drives were the friends of Eyvin Hernández. The Los Angeles public defender had been arrested in March 2022 when he illegally entered Venezuela from Colombia. The Hernández campaign waged a strong effort reaching government officials and doing effective lobbying.
Speaking of government officials, the removal of disgraced Democrat Robert Menendez as chair of the powerful Senate Committee on Foreign Relations eliminated a significant obstacle to the prisoner exchange. Surprisingly, Maduro revealed that a deal to free Saab had previously been made with Trump, but when Biden won the election, they had to start again from scratch.
The fourth and indispensable pillar for the successful campaign was Alex Saab’s family, who had been targeted by the US but stood firm and supportive. The day that Saab’s son turned eighteen, the US slapped him with sanctions along with his uncles and other family members. Camilla Fabri de Saab, the former prisoner’s wife, led the effort even though she was a young mother with two young children.
As would be expected, Fabri was initially devastated by her husband’s imprisonment. She too was targeted and even her parents in Italy were hit. But out of adversity came strength. Fabri took the lead in uniting the many pieces of the campaign and the legal effort. With no exaggeration, she became a major international leader. She was appointed by Maduro to be on the sensitive negotiating team meeting with members of the Venezuelan opposition in Mexico City to retrieve some of Venezuela’s assets that had been illegally seized by the US.
Fabri’s moving video, made just five days before her husband’s release, was about what the holidays would be like without him. As it turned out, this will be a more joyous holiday season for all the prisoners freed in this historic exchange and their families. The release of Alex Saab is a victory for Venezuelan sovereignty and shared with the third of humanity still under US sanctions.
Roger D. Harris is with the human rights organization Task Force on the Americas, founded in 1985. He has been active with the #FreeAlexSaab Campaign.
Keith Rankin, trained as an economic historian, is a retired lecturer in Economics and Statistics. He lives in Auckland, New Zealand.
Analysis by Keith Rankin.
Keith Rankin, trained as an economic historian, is a retired lecturer in Economics and Statistics. He lives in Auckland, New Zealand.
When countries’ national elections are closely fought, it means that the median voters critically determine the parliamentary or congressional outcome. But, though depending to a considerable extent on the prevailing political culture, the centre-of-gravity of the resulting government may be far from that median usually ‘centrist’ position of the voters.
The Aotearoan case
Aotearoa achieved something very rare in 1992 and 1993; a complete change of electoral system. Aotearoans were fed up with extremist winner-takes-all politics, where the ‘winner’ almost never got a majority of votes; and where the outcome in non-battleground electoral districts was purely academic, though ‘academic’ in the best sense of that word.
Ironically, the change was initiated by New Zealand’s ‘right-wing’ government of the last half century; the Bolger-Richardson National government which edged out the Lange-Douglas Labour government for this ‘honour’. (In both cases, the Prime Minister was comparatively ‘centrist’, but with extreme economic liberals as Ministers of Finance, although Roger Douglas was a relative latecomer to the cause of neoliberalism. In a sense, Prime Minister Jim Bolger did a ‘David Cameron’; expecting to put the matter of proportional representation to rest, just as Cameron expected his referendum in 2016 to dispel agitation for British exit ‘Brexit’ from the European Union.) We may also note that the Shipley-Birch government in 1998 and 1999 was very right-wing, having – in 1997 and 1998 – ousted both Prime Minister Bolger and Treasurer Winston Peters; in this case it was Prime Minister Shipley who was seen as more right-wing than Finance Minister Birch.
(There is some chatter – eg Chris Trotter, Nothing Left without Labour, 19 Dec 2023 – about as to whether the new government of Aotearoa New Zealand will be its “most right” ever. Time will tell of course, and there are alarming similarities showing between present Finance Minister Nicola Willis and 1990-1994 Finance Minister Ruth Richardson. For the last 100 years, I would rate the early Depression governments from 1930 to January 1933 as the most right-wing. This period from 1930, which commenced with the death in office of Prime Minister Joseph Ward, includes a Depression election at the end of 1931; an election which saw Labour, already in Opposition, trounced. In 1930 and 1932, Prime Minister George Forbes was also Finance Minister. In 1932 the extreme economic liberal, William Downie Stewart, was Finance Minister. In 1933, as in 1994, the government turned towards the political centre after the ousting of Stewart. The catalyst in 1933 was a critical change to monetary policy; the devaluation of the New Zealand pound which set New Zealand onto its eventual recovery path. Today’s byword for the 1932 and 1992 governments was ‘austerity’; we in Aotearoa sense – palpably – that austerity is also how the mid-2020s will be remembered.)
The hope in 1992 was that proportionally-elected governments would be loose coalitions, and that all parties in Parliament would contribute to some extent to the governance of New Zealand. And indeed we have seen that at times, with the ‘left-wing’ Green Party contributing to some policy delivery under a centre-right National-led government, and with the then radically-centrist Māori Party accepting the Prime Minister’s invitation to contribute formally to the governance process in the early 2010s.
The political culture in New Zealand – or at least the elite political culture – remained committed to binary politics; to the adversarial politics of Governments and Oppositions shouting at each other across a political theatre designed precisely for that kind of politics. As Peter Dunne – former leader of the former centrist United Party, a man who held the balance of power in three Parliaments this century – once said, the parties form into (or are formed into) “job lots” of the Left and the Right. In New Zealand’s history since 1996 of proportionally-elected governments, only three successful parties have resisted pre-election binarisation, and each only partially so: United, New Zealand First, and the previous incarnation of Te Pāti Māori (generally known then as the Māori Party).
As 2023 unfolded, it was looking like two distinct job lots would be fighting it out: National and Act as the Right; and Labour, Green and Te Pāti Māori as the Left. National and Labour were understood to be quasi-centrist neoliberal parties with nearly identical macroeconomic policies: fiscal conservatism laced with monetary austerity. But they had different political cultures: whereas National still represented the Old Right Elites (and rural New Zealand in general), Labour’s power base was the expanding New Left Elites, including the New Māori Elite. Elite politics – the politics of optics over substance, the politics of wilful neglect of the disadvantaged, and the politics of health and education mandates – was becoming increasingly adversarial, indeed becoming visceral.
Out of this cocktail of despair, Winston Peters’ nationalist New Zealand First Party – sometimes semi-radical, genuinely centrist – re-emerged, to the chagrin of the entire political class. But it New Zealand First had to be attached to the National-Act job lot. Peters and Labour had ruled each other out in 2022; and in a way that could not easily be undone. So one of the election campaign’s main ‘gotcha’ games was for the mainstream political media to force National leader Christopher Luxon to explicitly admit New Zealand First into his job lot of Parties, and then to blame Luxon’s ‘moment of weakness’ for Peters’ concurrent rise in the political polls.
The political polls had always indicated that the 2023 election would be a close – even ‘knife-edge’ – contest between the two designated job lots. The voters’ quandary was how to choose a moderate rather than an extreme government, given the relatively extreme positions on the left-right spectrum being taken by Te Pāti Māori, Green and Act. The quandary was exacerbated by the voters’ wish for a non-austere government, when both Labour, National and Act were firmly committed to fiscal austerity, and there was no intellectual commitment from Green or Māori towards an alternative to fiscal austerity.
(2023 was looking like an MMP – proportional – rerun of the 1931 and 1990 elections. We might note here that Joseph Ward’s United Party – unconnected to Peter’s Dunne’s more recent United – was a centrist party in the 1920s, the remnants of Richard Seddon’s Liberals. And, or at least it’s commonly believed, that Ward – then 72 years old, and perceived by some as a bit doddery – won the 1928 election because he misread his speech notes, and promised to raise a 70 million pound loan, when it’s believed he meant £7 million. Fiscal non-austerity is popular among the non-elite; and 1927 had been a terrible year for the New Zealand economy, under the public financial management of the fiscal ultra-conservative William Downie Stewart. More farmers walked off their farms in 1927 than in the Great Depression of the early 1930s.)
There is a party of the ‘radical centre’ in New Zealand – TOP, the Opportunities Party – but it never stood a chance of breeching the five-percent party-vote threshold in 2017, 2020, or 2023. And even TOP has deradicalised, presumably to edge closer to the mainstream fiscal narrative. I heard no mention from TOP or anyone else, in 2023, of a Universal Basic Income; a UBI, once TOP’s cornerstone policy, is counter-elite, hated equally by the elite left and the elite right. The message in 2023, to non-elite voters, was to vote for the elite job-lot they detested least, rather than to risk ‘wasting’ one’s vote on a party that couldn’t make the threshold. Since the first proportional election is 1996, no genuinely new party has made it past the five-percent barrier. (The ‘minor parties’ are all offshoots of ‘major parties’: the Green Party and Jim Anderton’s Progressive Party were offshoots of the Alliance, itself formed as New Labour, a Labour Party offshoot; Act was another offshoot of Labour; New Zealand First was an offshoot of National; Te Pāti Māori was an offshoot of Labour; United was an offshoot of both National and Labour.)
New Zealand voters have developed two techniques for moderating the left-right job-lot fait-accompli. They could tactically switch to United (as they did in 2002) or New Zealand First (as in 2005 and 2017) or the Māori Party (as they might have done in 2008 or 2017, but didn’t). The other possible tactic is for supporters of one of the ‘major parties’ – National or Labour – to switch to the other as a way of minimising the input in government of the minor party which they dislike the most. We saw that in 1999, 2008, and 2020. (In 2020, Prime Minister Jacinda Ardern called this other-party supporters “lending their vote” to Labour.)
What can happen is that a close ‘job-lot’ outcome – a close binary outcome between Left and Right – can increase the leverage in government of a small but extremist coalition partner. Act played that role of fear-nemesis to the Left, whereas Green is the traditional fear-nemesis of the Right. This is what is really meant by the ‘tail wagging the dog’; when an extremist party – or at least an adjudged extremist party – has excessive leverage, especially in close-election cases when the median voter supports a party like TOP.
Imagine if this present New Zealand government did not have its New Zealand First “hand-brake”, as Winston Peters accurately paints his intermittent role in New Zealand’s post-1993 proportional governance culture. That ‘hand-brake’ culture hasn’t developed to the point where the political class would be able to countenance a ‘grand-coalition’ of National and Labour. Indeed the median voter in New Zealand is not a bland centrist; not an elitist centrist. A bland-grand-coalition would only have the optics of centrist politics; it would not at all be in touch with non-elite voters.
Very few Prime Ministers in New Zealand have found a centrist position that’s in touch with middle New Zealand. Michael Joseph Savage did. Richard Seddon did. Joseph Ward did, briefly and too some extent inadvertently; but Ward wasn’t a fiscal conservative. And, perhaps belatedly, nostalgia is reviving the legacy of Robert Muldoon; he who helped New Zealand get through its second worst global economic crisis. On RNZ’s The Panel a few weeks ago, I heard someone suggest that Muldoon was New Zealand’s last “socialist” Prime Minister. To the great surprise of that show’s host, people texted in, in full agreement with that ‘last socialist’ proposition, and in a distinctly approving way.
Despite proportional representation, New Zealand’s political culture favours unpopular governments, and adversarial processes of rhetoric and repeal. Aotearoa New Zealand, one of the most privately indebted countries in the world can only elect governments which don’t pursue a ‘duty-of-care’ approach towards ordinary Aotearoans; the main parties are averse to spending money on social-wage services or universal public income support. Indeed, since 1994, ‘fiscal responsibility’ – read ‘wilful neglect’ – is embedded in the Public Finance Act; an Act which I would argue has become central to New Zealand’s de facto constitution.
To understand a political culture, comparisons need to be made with other political jurisdictions, with other sovereignties.
United States
The United States’ ‘parliament’ is Congress, elected on a two-year electoral cycle. Sometimes – like now – two years seems too long. The United States’ polity represents the ‘mother of all adversarial cultures’.
In the 2022 election, Congress flipped, giving the Republican Party a narrow win. That Republican Congress is significantly more extreme than just about any previous Congress, in large part because of the narrowness of its majority. This situation mainly arises because American culture has become so adversarial that the large Democrat minority voted with the Republican extremists to oust the Republican moderate – Kevin McCarthy – from his role as Speaker. (Speaker is the nearest to a Prime Minister that exists in the American system.) The result was an impasse of several weeks, and the eventual election of a Speaker – Mike Johnson – who is a conservative hardliner who endorsed the conspiracy theory that Donald Trump really won the 2020 presidential election.
In the United States system, close elections lead to more extreme outcomes, in complete contravention of the voters’ voice.
Israel
Israel has a proportional system, which allows for a much wider range of political parties than does New Zealand’s ‘MMP’ proportional system. The last two elections have been very close, with its multiparty ‘job lots’ only partly determined by the left-right political spectrum. Personality politics plays a big part.
Two elections ago the ‘man who would be king’ of Israel – Bejamin Netanyahu – was disempowered by an assortment of parties across the spectrum, including a small party supported by Palestinian Israelis. The temperature in this Levantine ‘powder-keg’ turned down a notch. But not for long. In the next election, with a sliver of a margin, Netanyahu was able to resume power by turning to the small ultra-Neozionist rump of his Parliament. The result is ‘history-in-the-present’, as we witness the brutal programmes to ethnically clear Gaza, and to squeeze the Palestinians out of any form of meaningful life in the West Bank and East Jerusalem. To maintain power during this electoral cycle, Netanyahu has no choice but to fall in line with his government’s most extreme voices. For perhaps most Israelis, the next election cannot come soon enough.
Again, given the prevailing political culture, close elections can lead to extreme outcomes.
France
In France – a European exception, without proportional representation – there has been a complete turnover of major parties. France’s equivalents of National and Labour both died in the 2010s. Neither seems capable of resurrection. In their place is a centre party – Renaissance – that looks like a mini-grand-coalition, a populist right party, and a new leftwing alliance. There are no multiparty job-lots as such; rather each party itself is a coalition of factions. A degree of stability is ensured by the two-ballot system; a system that was used in Aotearoa New Zealand in 1908 and 1911, but abolished in 1913 by one of New Zealand’s most right-wing governments (led by William Massey), and one with a paper-thin majority. (Massey’s first government formed mid-term when ‘Independent Liberal’ Gordon Coates was coaxed by Massey to join the conservative Reform Party. Massey’s first action was to abolish the two-ballot system – effectively preferential voting as in Australia – and return to the First Past the Post system whereby many elected representatives receive well under half of all votes cast.)
Under its present configuration of parties, it’s hard to see how Emmanuel Macron’s Renaissance Party cannot control France’s parliament. So, it will be the back-room coalitions which determine the extremity or otherwise of future French parliaments.
United Kingdom
The next election in the United Kingdom looks like being fought between a divided – and somewhat conservative Labour Party – and a Conservative Party which has outstayed its welcome. I am guessing that the centrist Liberal Democrats will score well, though the outcome will be determined by the balance of unpopularity between Labour and Conservative. If the balance of unpopularity is a fine one, and the Liberal Democrats go for a programme like that in New Zealand of TOP, then the United Kingdom may eventually achieve an outcome in line with popular appeal. But there are many ‘ifs’ and ‘maybes’.
The United Kingdom has had a deeply frustrating time with its democracy, of late. The point to note here is that those people voting for large small parties – like UKIP in United Kingdom, and the former Social Credit in New Zealand – and people in ‘safe’ constituencies, are rendered invisible to the elite political classes. One result is that David Cameron made a huge political mistake in 2015, promising a referendum on the United Kingdom’s membership of the European Union. The unexpected outcome was the result of a rare opportunity by those rendered invisible by the First Past the Post system, to render themselves visible.
Germany
Germany uses the MMP proportional system, the prototype of the New Zealand system. Before World War Two it had a different proportional system, with lower thresholds. As is well known, Germany gained a very extreme government in 1932, as the Great Depression peaked; a great depression made especially severe by both the post World War One Treaty of Versailles and the needless fiscal conservatism (ie austerity) of the centre-left coalition government prior to 1932. The Nazi Party came into the Bundestag (Parliament) on an anti-austerity economic programme, revealing its true colours (of national expansionism and ethnic scapegoating) later, once entrenched in power. The path to the Nazi outcome was a leftish government pursuing deflation, extreme fiscal conservatism; a mix of austerity and unimagination.
Elections were held in Germany in May 1928 (2.6% to the Nazis), Sep 1930 (18.3% to the Nazis), July 1932 (37.3% to the Nazis), Nov 1932 (33.1% to the Nazis), March 1933 (43.9% to the Nazis), and Nov 1933 (92.1%! to the Nazis). Before the Great Depression the Nazi party was a ‘lunatic fringe’ party. Adolf Hitler rode to power on the path of political instability and fiscal austerity.
In Germany today, while the parties in the present Bundestag cover a wide spectrum of ideologies, the post-war culture is to form coalitions around the centre, especially in a very close election. The problem is that the centre in Germany – defined by the Social Democrats (like NZ Labour) and the Christian Democrats (like NZ National) – is a centre of bland fiscal conservatism and of export-focussed mercantilism. We should not look to Germany to find solutions to the world’s financial problems.
New Zealand again
In New Zealand, consider these three-election sequences. The statistic quoted will be the percentage of votes for the parties to the left of (and opposed to) the leading conservative party.
centre-left
1928
59.8%
1931
46.0%
1935
58.4%
1972
57.9%
1975
52.3%
1978
59.5%
1987
55.3%
1990
51.3%
1993
62.3%
2005
58.5%
2008
48.7%
2011
48.3%
In each case, in the middle year, National (or its equivalent, Reform) swept to power, following centre-left governments which had ‘lost their mojo’.
In the first three cases (all first-past-the-post elections) the centre-left subsequently swept back in the popular vote. (Though, thanks to the prevailing voting system, in 1978 and 1993 there was no change of government. Even in 1935, Labour’s route to power may have depended on a split in the right-wing vote; the extreme-right Democrats got 7.8% of the vote, and split the vote in many electorates.) The centre-right governments of 1931, 1975 and 1990, which lost favour massively in the subsequent election, moved away from policies of austerity; real austerity (in 1993) or perceived austerity (in 1978).
In 2011, something different happened. The centre-left failed to get its vote back. Labour was looking very divided and uncool, whereas the National-led government managed its optics well, taking credit for a re-emergence from the Global Financial Crisis. Part of that political management was the creation of the impression that the 2008 to 2011 government was more centrist than right-wing.
What will happen in 2026? Just now I heard Sue Bradford – former Green left-wing MP – comparing this new government with the National government elected in 1990. I think she’s correct. My sense is that the present government is as intent on making itself unpopular as that early 1990s’ government was. (Indeed both Finance Ministers were young; Ruth Richardson was 40, and Nicola Willis is 42.)
The difference is that Labour (with the other centre-left parties in Labour’s job lot) also gives the appearance that it is similarly intent on retaining their 2023 levels of unpopularity; as they were in 2011 after 2008, and also as the British Labour Party did after Margaret Thatcher gained power in the United Kingdom in 1979.
The 1935 to 1938 Labour government also gained a degree of unpopularity, with left and right factions seeking to find ways to renege on its radical centrist promises of universal social security and superannuation. In the end it was Michael Joseph Savage’s political skills in 1938 that enabled Labour to storm to victory in 1938, and to stay in power for 14 years. New Zealand voters are looking forward to a non-austere non-elitist non-ideological government in 2026; a government with pragmatic imagination (no, that’s not an oxymoron). Good luck to Jo and Joe Median.
*******
Keith Rankin (keith at rankin dot nz), trained as an economic historian, is a retired lecturer in Economics and Statistics. He lives in Auckland, New Zealand.
Painful periods are common. More than half of people who menstruate have some pain for up to three days a month, typically throbbing or cramping in the lower abdomen.
Digestive changes – such as vomiting, gas, bloating, diarrhoea and a “bubbling gut” – are also common around the time of menstruation.
There are many treatments for period pain (known medically as dysmenorrhoea). Not all these treatments are well-tolerated or work for everyone.
We’re learning more about food’s role in influencing inflammation in our body. So, could eating or avoiding certain foods help with painful periods? Here’s what we know based on high-quality research.
Foods rich in omega-3 fatty acids include chia seeds, walnuts, flaxseeds, salmon, herring, sardines, mackerel, oysters and edamame beans. Omega-3 fatty acids are naturally present in oils including fish, cod liver, algal, krill, flaxseed (linseed), soybean and canola oils.
Omega-3 fatty acids affect how our cells function and the signalling pathways associated with inflammation and pain.
Earlier this year, researchers published a meta-analysis where they combined and analysed all data available on the impact of omega-3 fatty acids on period pain. They found diets high in omega-3 fatty acids (including supplements of 300-1,800 milligrams a day) over two to three months may reduce pain, and pain medication use, in people with painful periods.
Foods high in vitamin D include trout, salmon, tuna and mackerel, as well as fish liver oils. Small amounts are also found in beef liver, egg yolk and cheese. Mushrooms contain varying levels of vitamin D, and you can boost this by exposing them to direct midday sunlight for 15-120 minutes.
The body can make vitamin D when it gets sunlight exposure and you can also get vitamin D from supplements.
Vitamin D may help reduce the factors that cause inflammation in the uterus. This includes levels of hormone-like molecules called prostaglandins.
A 2023 meta-analysis showed women who received weekly doses of vitamin D greater than 50,000 IU (or international units) had relief from period pain, regardless of how long and how often women took the vitamin.
Foods rich in vitamin E include seeds (particularly sunflower seeds), nuts (particularly almonds, hazelnuts and peanuts) and spinach, broccoli, kiwifruit, mango and tomato.
There is some evidence vitamin E supplements reduce period pain. In a well-conducted trial run over the course of four periods, women took vitamin E supplements (90 milligrams, twice a day) for five days, beginning two days before the expected start of the period. This significantly reduced the severity and duration of period pain.
Highly processed foods include energy-dense, nutrient-poor foods such as takeaways, chips, biscuits, doughnuts, processed meats and soft drinks.
Research findings on the impact of a diet high in processed foods on period pain vary. A 2022 review found sugar consumption had little association with painful periods.
However, some observational studies (which do not involve an intervention) suggest women who eat more processed foods may have more intense period pain. For example, a 2009 study found adolescent females who ate fast or processed foods for two days or more a week reported more period pain compared with those who did not. Therefore, eating less processed food may be something to consider.
Foods high in caffeine include coffee, energy drinks and some processed energy bars. Caffeine intake is associated with menstrual pain.
Although we don’t know the precise underlying mechanism, researchers think caffeine may narrow blood vessels, which limits blood flow, leading to stronger cramps.
Drinking alcohol is not a recognised risk factor for painful periods. However, chronic heavy alcohol use reduces levels of magnesium in the blood. Magnesium is an important factor in relaxing muscles and supporting blood flow.
Having a healthy, balanced diet is one of the best ways we can support our own health and prevent future chronic conditions. This can help reduce inflammation in our bodies, thought to be the main way diet can help people with painful periods.
If you are looking for tailored dietary advice or a menstrual health meal plan, speak with an accredited practising dietitian.
It’s important to stress, however, that diet alone cannot treat all forms of menstrual pain. So if you are concerned about your painful periods, check in with your GP who can discuss your options.
Lauren Ball works for The University of Queensland and receives funding from the National Health and Medical Research Council, Queensland Health and Mater Misericordia. She is a Director of Dietitians Australia, a Director of the Darling Downs and West Moreton Primary Health Network and an Associate Member of the Australian Academy of Health and Medical Sciences.
Emily Burch is an Accredited Practising Dietitian and member of Dietitians Australia. She works for Southern Cross University.
Pui Ting Wong is a PhD Candidate at The University Queensland (UQ) Centre for Community Health and Wellbeing, and receives the UQ Tuition Fee Offset and Stipend Scholarship. She is also an Accredited Practising Dietitian and a member of Dietitians Australia.
As part of its coalition deal with National, the ACT Party is preparing to resurrect its “regulatory responsibility” legislation for the fourth time. This is despite the idea having been consistently rejected since 2007.
As ACT’s coalition partners decide whether to allow its Regulatory Standards Bill to succeed this time, they need to reflect on that historical context.
ACT’s definition of “regulation” goes beyond parliamentary laws to include all forms of regulation at all levels of government. Its bill requires new (and eventually all) such regulation to adhere to principles and processes, also defined by ACT. It would also allow the courts to issue declarations of non-compliance.
The proposal is an extension of the neoliberal rhetoric of “best practice regulation”, including regulatory impact assessments and statements, which has become embedded in government practice since the 1990s. It has been endorsed by both National-led and Labour-led governments.
The 1999-2008 Labour government embraced the notion of “risk-tolerant regulation”. Essentially a market-based approach, it spanned a spectrum from no regulation or self-regulation to co-regulation with government. Hands-on regulation was a last resort.
This minimalist approach assumed businesses would honestly and rigorously monitor themselves, and report on their compliance based on those loosely framed principles. Government agencies, meanwhile, would limit regulation based on risk assessments and cost-benefit analyses.
The origins of ACT’s latest push for regulatory reform lie as far back as the 1980s and 1990s, when the Labour finance minister, Roger Douglas, and his National Party successor, Ruth Richardson, ushered in core pieces of legislation: the Reserve Bank Act 1989, State Sector Act 1988, Public Finance Act 1989 and Fiscal Responsibility Act 1994.
A Regulatory Responsibility Act was the missing piece. In my 2015 book The FIRE Economy, I explained its significance as “meta-regulation”. In effect, it was designed to regulate the way governments regulate. It institutionalised a pro-corporate approach of self-regulation, light-handed regulation, or no regulation at all.
The neoliberal Business Roundtable think tank (now the New Zealand Initiative) began pushing the idea of an “economic constitution” in the early 1990s. A 2001 report for the Roundtable by former Treasury director Bryce Wilkinson, titled Constraining Government Regulation, contained a draft Regulatory Responsibility Bill.
This required all future laws and regulations to comply with a selective list of libertarian principles. These encompassed aspects of the rule of law, protection of individual liberties and property rights, and restrictions on the imposition of taxes and charges.
It also sought to embed “good law-making processes”, including cost-benefit analyses and prioritising non-regulatory options. Public entities would have to review their relevant laws for compatibility with the principles.
Significantly, it also empowered the courts to review legislation. Individuals could ask the courts to declare that new laws breached these regulatory standards, and after ten years could seek a judicial declaration on pre-existing laws.
The bill that wouldn’t die
ACT adopted the Roundtable’s draft bill, which was drawn from the ballot in the name of party leader Roger Douglas after the 2006 election. (Douglas had by then left the Labour Party to co-found ACT in 1993.)
A renamed Regulatory Standards Bill was introduced in 2011. Constitutional experts attacked its selective principles, and objected that judicial declarations of non-compliance with those principles would potentially involve judges in making political decisions.
The bill was also silent on Te Tiriti o Waitangi/the Treaty of Waitangi. The Legislative Advisory Committee opposed it. And the Treasury used the same regulatory impact process ACT’s bill championed to oppose it.
Arguing the bill lacked necessary broad-based support, and that compliance costs would exceed benefits, Treasury favoured the alternative of strengthening the parliamentary review process.
The third attempt to introduce the bill, by ACT leader David Seymour in 2021, fell at the first reading, although National (by then in opposition) supported it.
Considering this history, it is likely the same grounds for opposing ACT’s regulatory responsibility campaign will be rehearsed in select committee once again.
The potentially significant budgetary impacts of a proposed ministry of regulation, reviews and repeals of existing regulation and revisions of the current regulatory toolkit are also uncosted (despite ACT’s insistence on “fiscal responsibility”).
There is some irony, too, in ACT’s election promise to rein in “knee-jerk, populist laws”. The coalition government is implementing its 100-day plan with little pretence of “good regulatory” process, or even select committee hearings.
Already, the dual Reserve Bank objectives, fair pay agreements, smoke-free and employment laws – which all originally went through the regulatory impact assessment and statement process – have been repealed under urgency.
The government has also refused to release a draft regulatory impact statement for its bill to repeal the Clean Car Discount Act (which has implications for New Zealand’s ability to achieve its climate goals) until after parliament votes.
ACT’s Regulatory Standards Bill may yet meet trenchant and terminal opposition again. But perhaps its introduction will lead to a broader revisiting of the neoliberal model of “meta-regulation”, and how it has served Aotearoa New Zealand over the past 40 years.
Jane Kelsey received a Marsden Fund grant in 2009 to examine embedded neoliberalism in Aotearoa New Zealand, including the neoliberal regulatory regime and the Regulatory Responsibility Bill.
Much has been made of the increasing presence of the “bank of mum and dad” in the lives of Australians.
We know financial support from parents to adult children is increasingly used for entering the housing market.
But our new research shows parents are also helping their young adult children in other ways, including with meeting everyday expenses. We’ve gained new insights into who is receiving support from parents and what it’s used for.
So what does this look like in practice, and what does it mean for intergenerational inequality in Australia?
We have surveyed a diverse group of young Australians for almost 18 years, since they were in year 12 in 2006. This has allowed us to follow the trajectory of a cohort of millennials as they have transitioned to adulthood.
One of the areas we ask about is their sources of financial support. This includes their own income, savings and investments, and government support, but also gifts, loans and other transfers from their family.
Our findings show that financial support from family – typically parents – has become important for this generation well into young adulthood.
This support from family was very common for our participants when they were in their late teens. Perhaps more surprisingly, for many this support continued into their 20s and, for a significant minority, into their late 20s and beyond.
So is it only rich parents providing this assistance? Turns out, not really. Our results show young adults from diverse socioeconomic backgrounds get financial help.
Surprisingly, the educational level and occupation status of their parents did not predict whether our participants were receiving support. Parents with higher education and in managerial or professional careers are providing financial help. But so too are parents of more modest means, even if the amount of support they can provide clearly differs.
It’s not just about houses
Our participants are using this support to pay basic expenses.
One in five 32-year-olds in our study report struggling to pay for three or more basic expenses (we ask about food, rent or mortgage repayments, house bills and healthcare costs). These young adults are three times more likely than those not facing this struggle to report receiving financial support from their family.
These gifts and loans are also used to support parenting, and to support those working part-time out of choice or necessity.
Some of our participants working part-time in their late 20s and early 30s are not in such a precarious position. They are receiving parental support while they pursue graduate study in medicine or law, for example.
So while some are using support to meet day-to-day needs, we also see parents helping their children “get ahead”.
Financial support is also used to pursue extended education and manage a period of insecure and poorly paid employment on the way to more secure and well-paid careers in medicine, academia or journalism.
This intergenerational support has social ramifications that go beyond buying property. Our research suggests it also shapes education pathways, employment, parenting, and potentially general wellbeing.
Our results are an example of just how much life has changed in Australia. The growing challenges of cost of living and the effects of a booming housing market over many decades are changing the dynamics of inequality.
Most of the parents’ generation of the young people we have tracked are part of the Baby Boomer cohort. While there is substantial economic inequality within it, overall, this group benefited from the housing and other asset booms over recent decades.
Many parents are using this foundation to help their children well beyond their teenage years. Of course, wealthy parents might find it easier to provide this support but are not the only parents providing it. For less wealthy parents, this might potentially change their plans for their own future and retirement.
Previous research has highlighted that the bank of mum and dad is becoming crucial for buying a house and that this might exacerbate and entrench inequality for future generations.
Our work suggests it goes beyond housing. Parents are helping combat financial insecurity for their young adult children across the board. Our data shows this widespread insecurity emerged before the current cost-of-living crisis, but current conditions are going to exacerbate it.
So we need to ask whether we want the bank of mum and dad to continue to play an ever-growing role in life chances in Australia. Based on our research, that change is already underway.
Dan Woodman receives funding from the Australian Research Council.
Julia Cook receives funding from the Australian Research Council.
Quentin Maire does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointments.






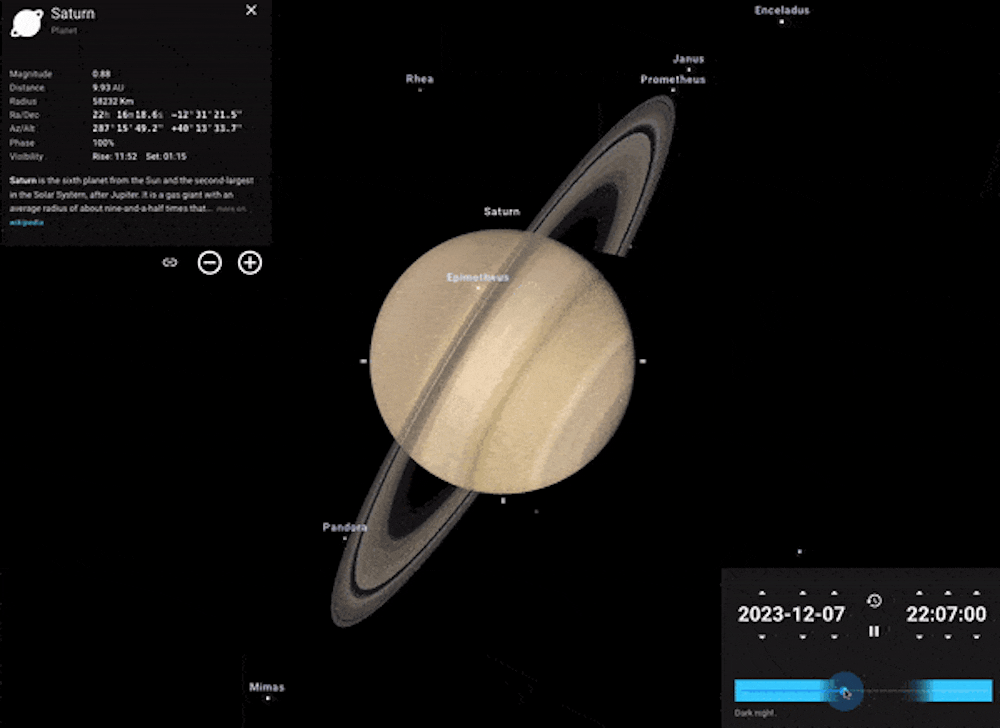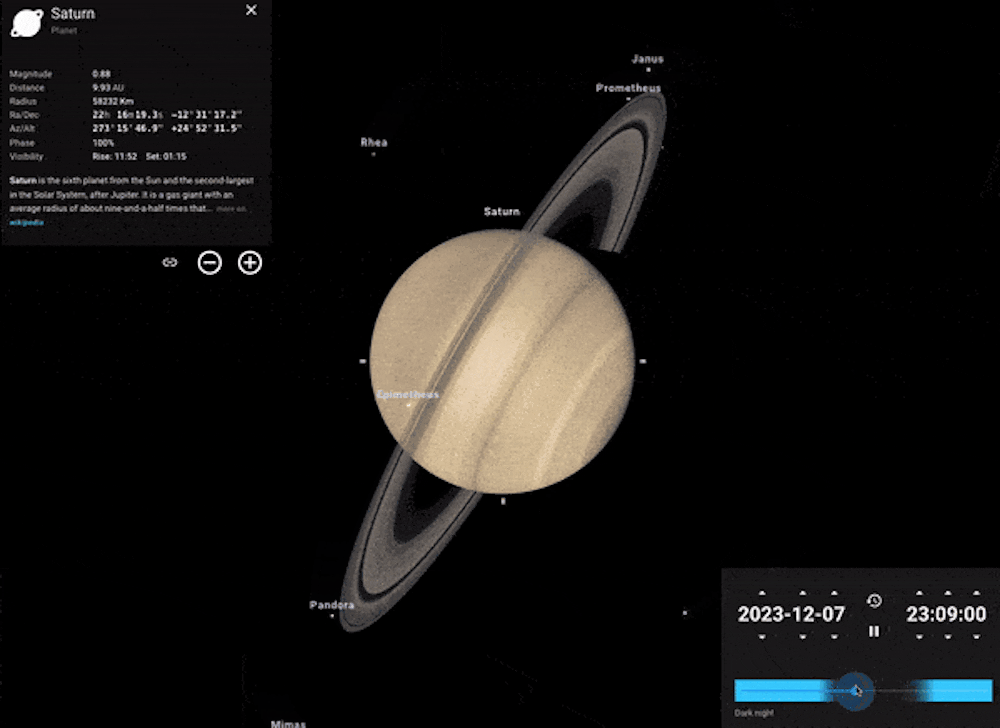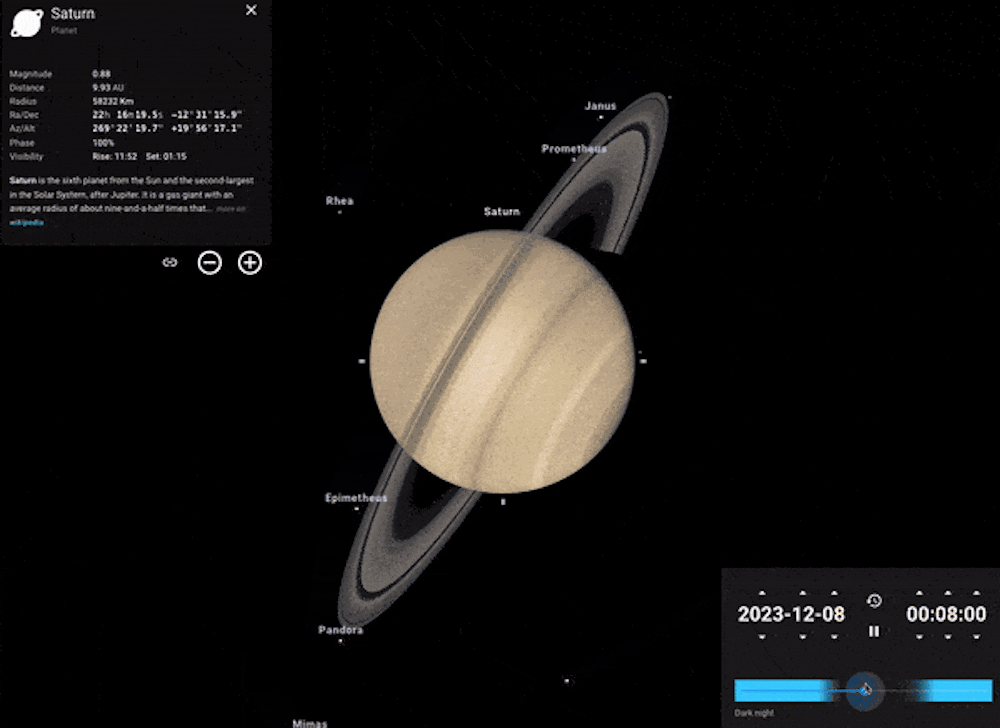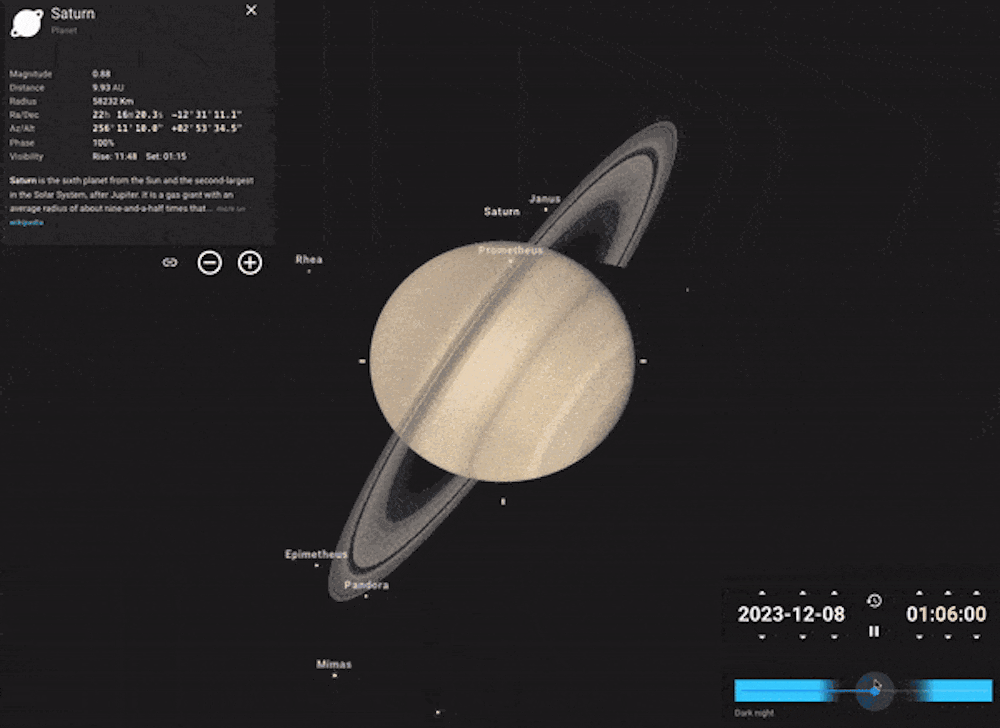












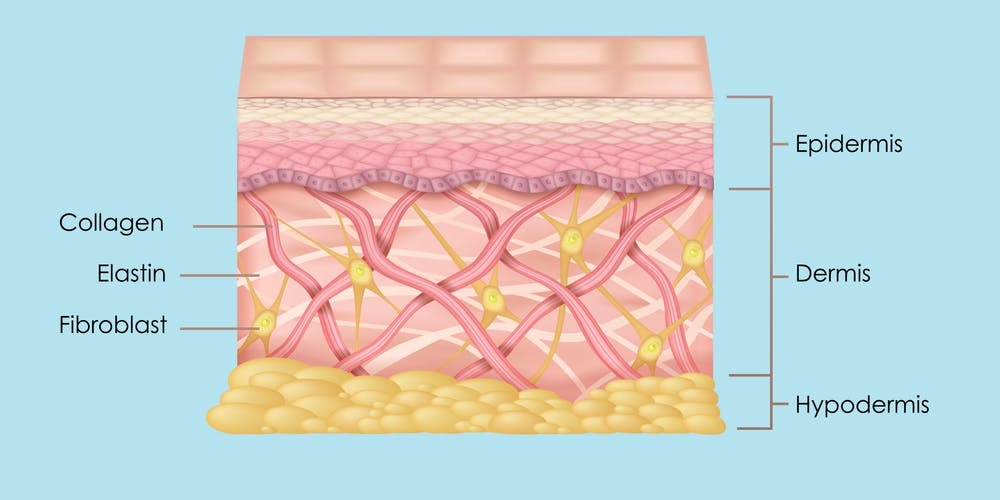
































































.jpg){kind=link}
{kind=link}